Olá a todos,
Hoje, no seguimento do tema de um dos nossos últimos posts, continuaremos a nossa viagem pelo mundo da IA.
Desta vez, a viagem será pelo processo de carregamento de novos modelos de machine learning na nossa instancia de Ollama2, vindos diretamente de uma comunidade de AI que dá cartas sobre o tema.

O que é o Ollama2?
Para aqueles que estão a perguntar “O que raio é o Ollama2?”, e não leram o meu ultimo post sobre o tema permitam que vos informe: O Ollama2 é uma plataforma LLM incrível – e muito fácil de ter em ambiente on-premise ou self host – que permite aos entusiastas de machine learning carregar e compartilhar seus próprios modelos treinados, facilitando assim a colaboração e fomentando a exploração que é o motor da comunidade de IA.
Porque carregar novos modelos?
A resposta a esta pergunta é realmente simples: diversidade e inovação! Ao adicionarmos novos modelos á nossa instancia de Ollama2, estamos a amplificar o leque de ferramentas disponíveis para resolver problemas. Por exemplo, resumir um documento, ou escrever um texto, ou até escrever código. É algo que abre espaço para criatividade e descobertas surpreendentes.
Vejam isto como o paradigma de não aparafusar um parafuso com um martelo, ou martelar um prego com uma chave de fendas. Uma ferramenta adequada para a tarefa especifica.
Como carregar novos modelos?
Tecnicamente o desafio tem duas formas de ultrapassar. Uma das quais pode parecer intimidante à primeira vista, mas não se preocupem – é extremamente fácil e simples de efetuar.
Passo 1: Preparem-se
Antes de começar, certifiquem-se de teem o vosso Ollama2 a escutar as portas necessárias e que tem acesso de consola/ssh ao mesmo.
Passo 2: Faça o Upload/Download do ML desejado.
Nota: O método mais habitual – que é através da webui – já foi apresentado no post anterior sobre o tema. Esta forma especifica descrita abaixo, implica acesso por consola ao sistema que está a executar o nosso ML
Escolham o modelo que melhor se adequa á vossa necessidade. No meu caso, irei instalar um deepseek-coder:q5 que para mim, e para o que quero, contem o perfeito equilíbrio entre o que necessito e os recursos que tenho disponíveis para o fazer. Notem porem que o deepseek-coder:q5 vem num formato que a webui não consegue gerir para carregar, razão pela qual apresento o seguinte procedimento.
Em primeiro lugar, navegar até á pagina huggingface que é como um search engine para modelos de ML:

Em seguida no search field, procurar por deepseek-coder. O resultado será algo como isto:
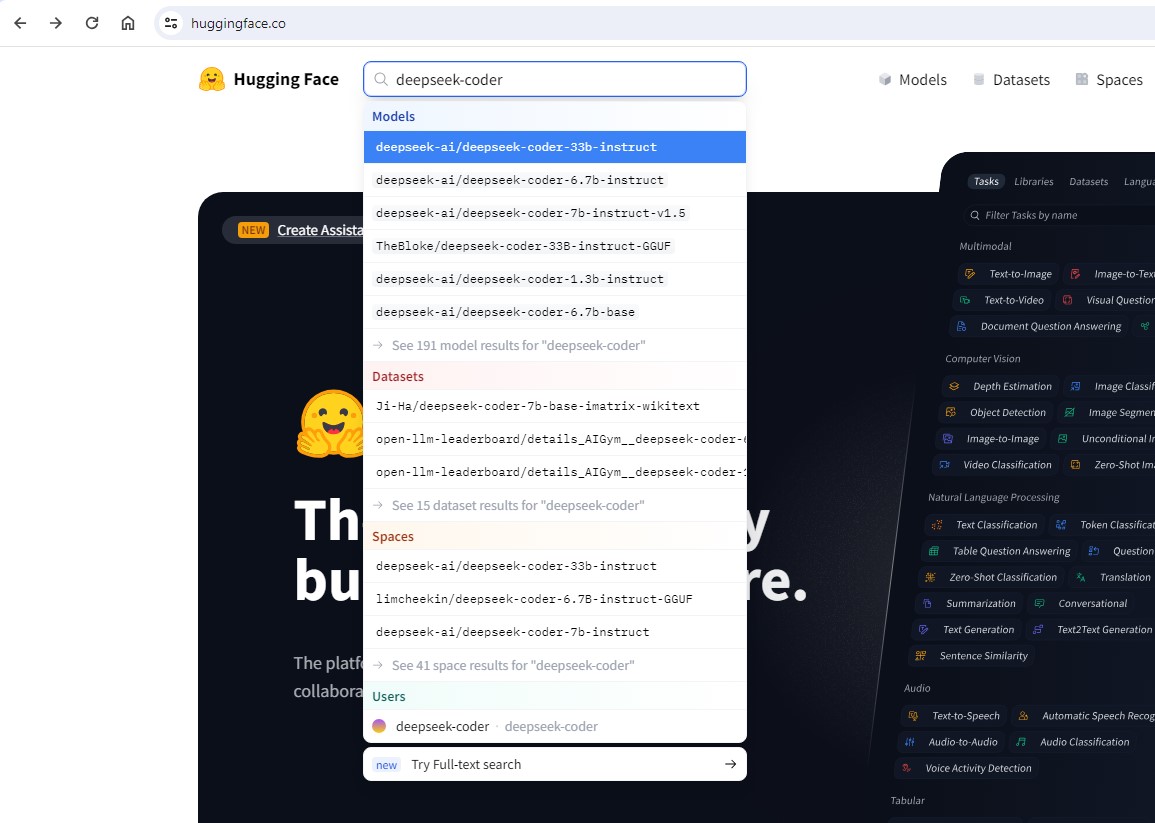
De todos os campos que são apresentados, estamos particularmente interessados em campos que tenham a referencia GGUF que é um “formato” que o nosso Ollama2 consegue carregar sem grande dificuldade via o CLI nativo (consola), mas não através da webui:
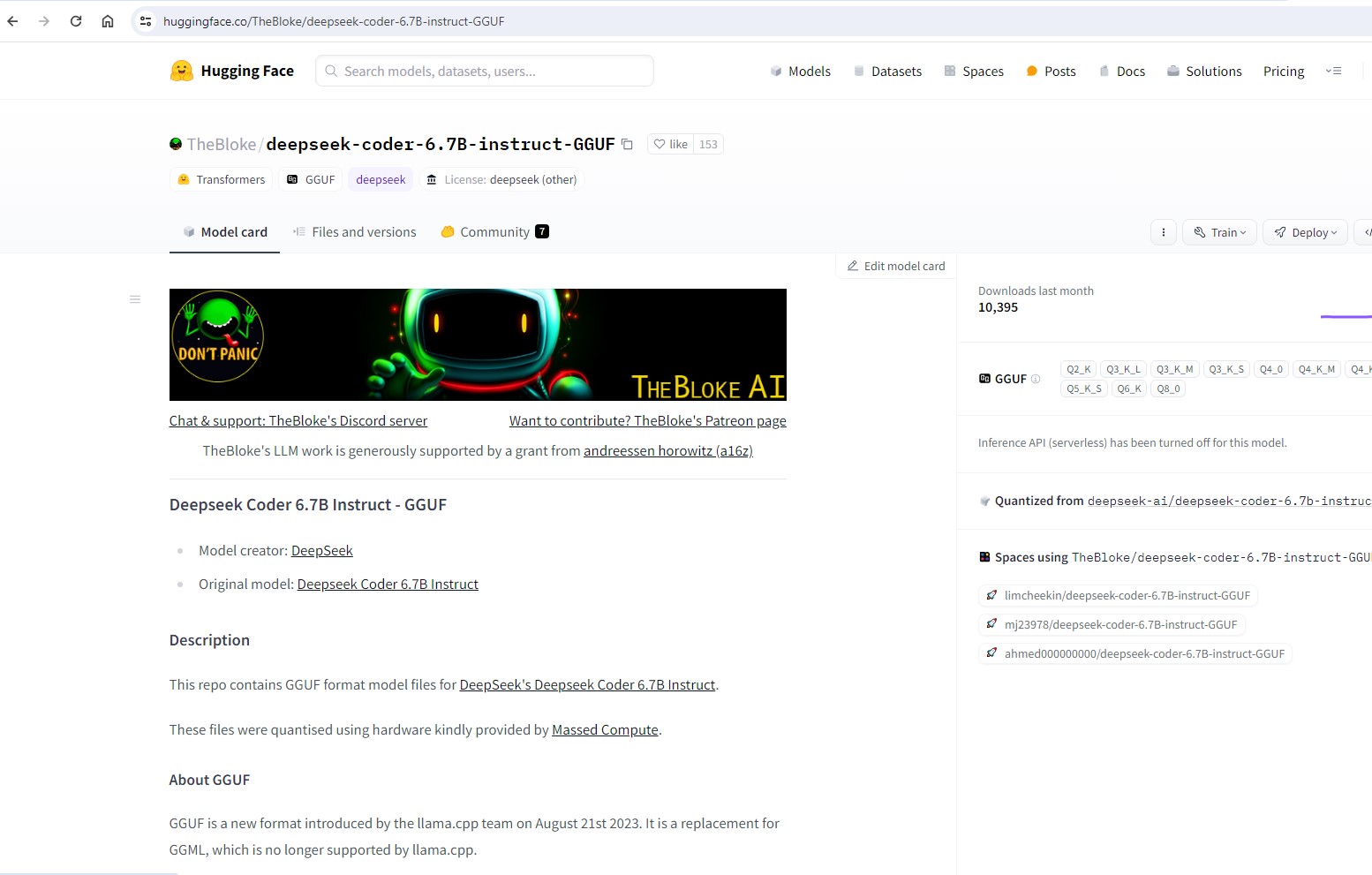
Em seguida, files and versions:
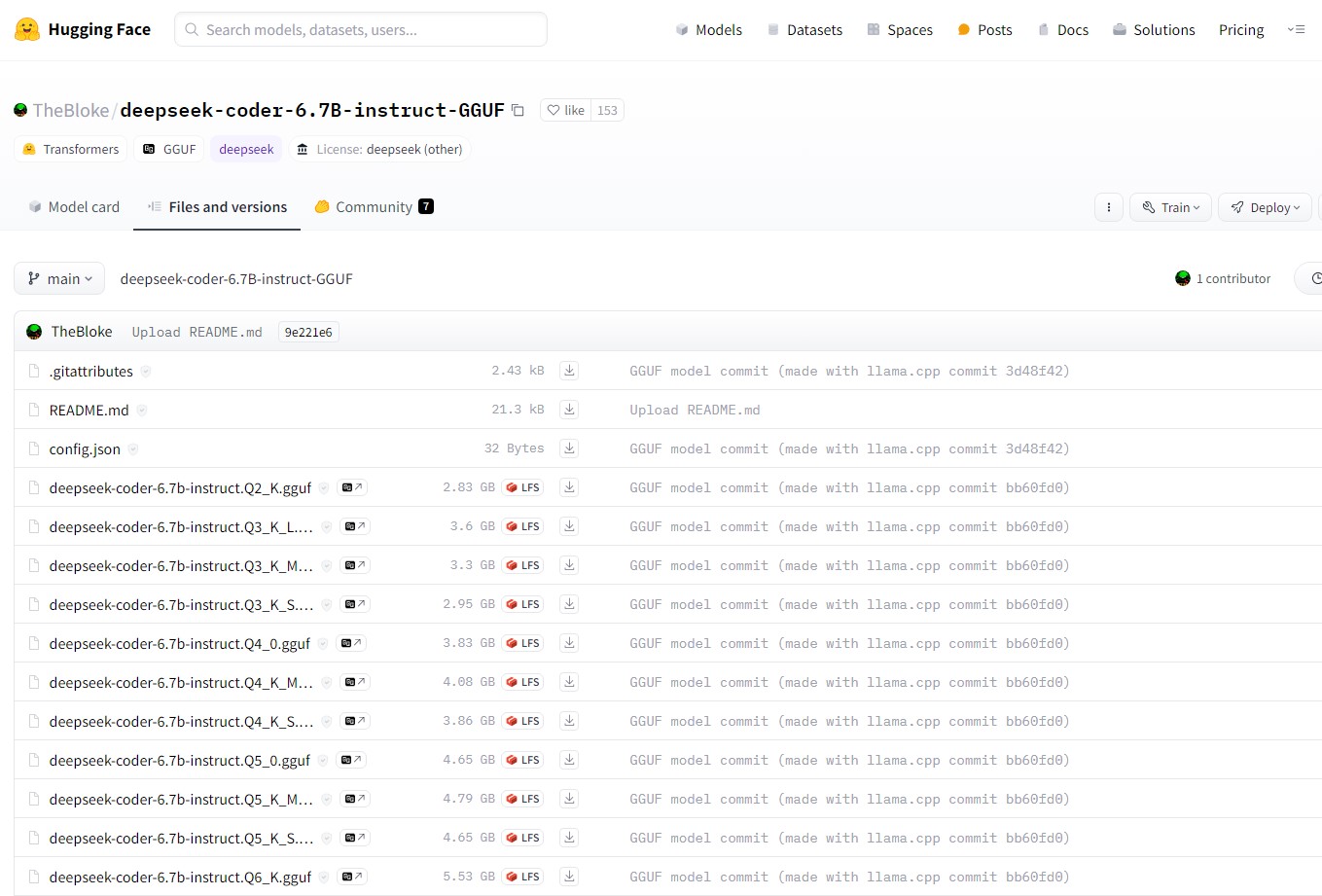
Em seguida, escolher o ML model que nos interessa mais. Para mim, descobri que os modelos Q5 tem o melhor equilíbrio entre qualidade de resposta e tamanho/carga no sistema:
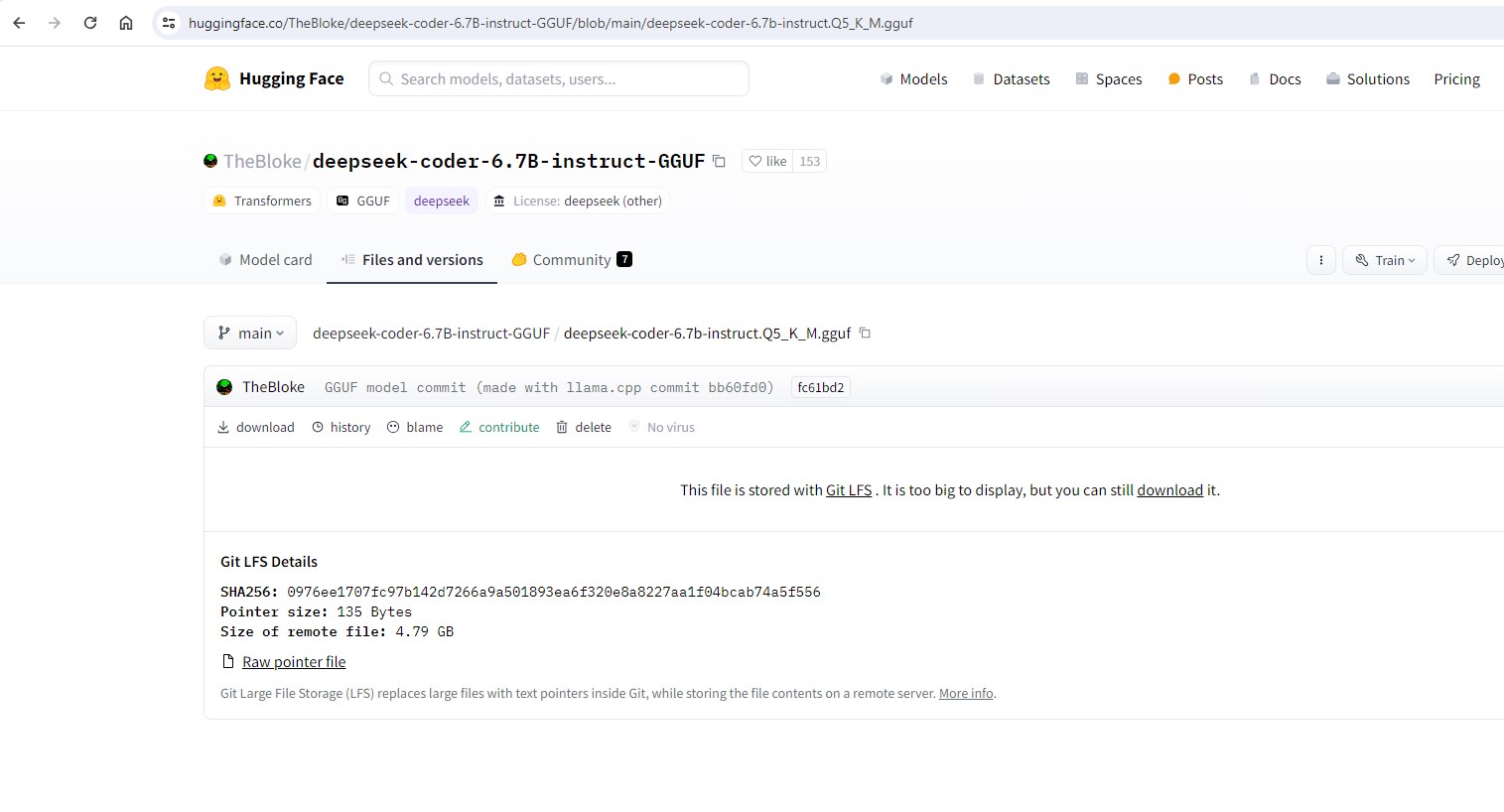
Em seguida, descarregar o ficheiros (copy do link de download):
wget "https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/resolve/main/deepseek-coder-6.7b-instruct.Q5_K_S.gguf?download=true" -O deepseek-coder-6.7b-instruct.Q5_K_S.gguf
Agora, é hora de aguardar o download e passar ao passo 3.
Passo 3: Preparação para carregamento do novo modelo de ML no nosso Ollama2
Para carregar o nosso novo modelo, é necessário construir um “template” file com as instruções do modelo:
FROM /models/deepseek-coder-6.7b-instruct.Q5_K_S.gguf
TEMPLATE """### System:
{{ .System }}
### User:
{{ .Prompt }}
### Assistant:
"""
PARAMETER num_ctx 4096
PARAMETER stop "</s>"
PARAMETER stop "### System:"
PARAMETER stop "### User:"
PARAMETER stop "### Assistant:"
PARAMETER num_thread 23
Nota: Na secção from indicar a full path do nosso ficheiro gguf descarregado no passo anterior. No meu caso, foi descarregado para uma diretoria chamada /models.
Alterar igualmente o numero de threads de CPU que querem que o vosso ML utilize. No meu caso, 23 threads.
Passo 4: Carregamento do novo modelo de ML no nosso Ollama2
Agora que temos o nosso template pronto, chegou a hora na consola, de carregar o ML em si no nosso Ollama2
# ollama create deepseek-coder-6.7b-instruct.Q5:latest -f model_deepseek-deepseek-coder-6.7b-instruct.Q5_K_S
O Ollama2 irá carregar o vosso template e modelo, e no fim o resultado será algo como:
# ollama list NAME ID SIZE MODIFIED deepseek-coder-6.7b-instruct.Q5:latest f7362531c16f 4.7 GB 2 weeks ago
# ollama show --modelfile deepseek-coder-6.7b-instruct.Q5:latest
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM deepseek-coder-6.7b-instruct.Q5:latest
FROM /usr/share/ollama/.ollama/models/blobs/sha256:1362c06f3036b4c4994bd8497ecbc0b487acb67e568b4addb4b17fc1e863f688
TEMPLATE """### System:
{{ .System }}
### User:
{{ .Prompt }}
### Assistant:
"""
PARAMETER num_ctx 4096
PARAMETER num_thread 23
PARAMETER stop "</s>"
PARAMETER stop "### System:"
PARAMETER stop "### User:"
PARAMETER stop "### Assistant:"
O resultado final será igualmente visível na vossa webui (alem deste tenho váriosoutros que estou a testar):
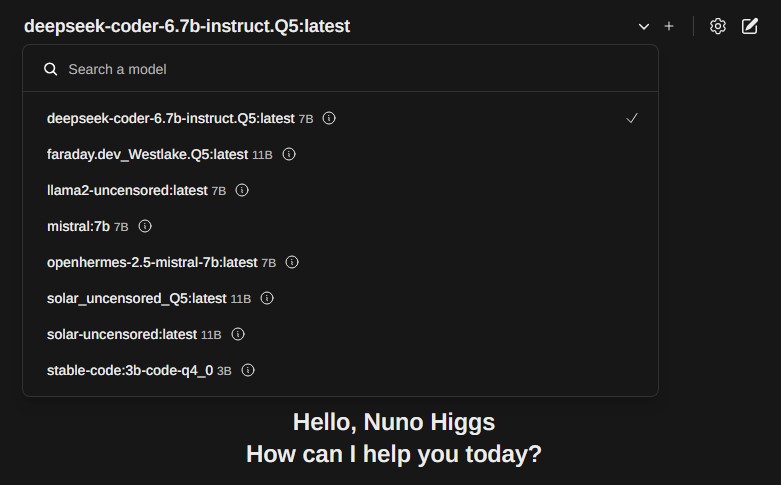
Podemos em seguida fazer questões direcionadas a tarefas de programação:

A resposta foi algo como:
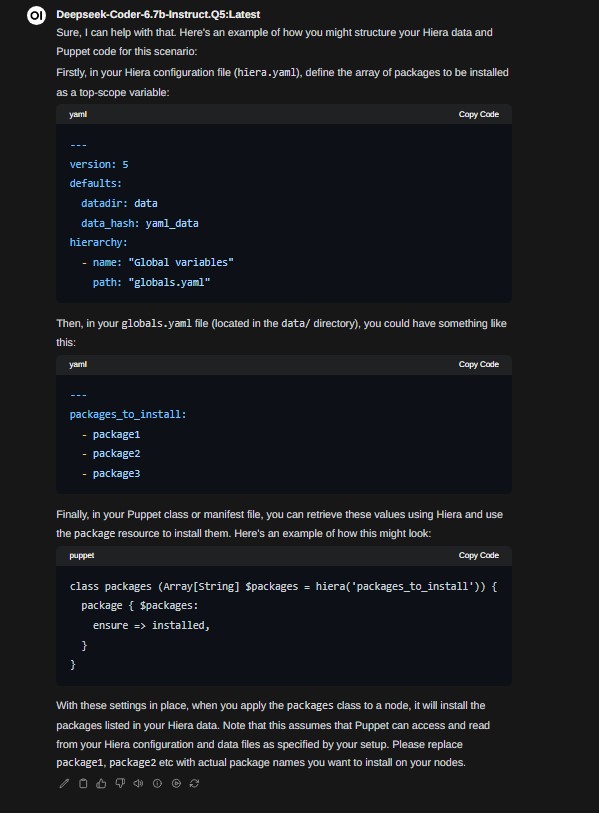
E pronto chegamos ao fim de mais um post semanal. Em breve vos trarei as minhas escolhas pessoais (algumas já são visíveis nessa imagem com o dropdown dos modelos que estou a executar) e as escolhas da comunidade sobre o tema.
Irei ainda explorar funções como o RAG que podem em muito nos simplificar o dia.
Até ao próximo post, e já sabem onde me encontrar caso encontrem algum ponto menos correcto.
Abraço!
Nuno