Olá a todos,
Quem ainda não ouviu falar de IA?
E quem ainda não ouviu falar dos alertas do risco de partilharem dados da vossa empresa com entidades externas, através de uploads para IA’s publicas?
E se eu vos dissesse que podemos ter IA privada ao nosso dispor, de forma fácil e segura? Hoje iremos falar precisamente disso. De ter uma IA a correr em ambiente selfhosted/on-prem e como isto é importante para quem trabalha no nosso ramo.
Disclamer: A politica da vossa empresa por explicitamente proibir a transferência de dados para fora do perímetro de rede deles. Assim sendo, por favor, entendam se podem ou não transferir dados para a vossa IA, ou se esta transferencia poderá colocar a vossa empresa ou o vosso posto de trabalho em risco.
Eu no meu dia a dia utilizo muito componentes de IA para validar código que escrevo, para construir expressões regex – que não estou muito a vontade para fazer – e em alguns casos, experimentar variações de modelos LLM para aprender como funcionam.
No entanto, e como referi no disclamer anterior, por motivos de privacidade do código de alguns clientes, não posso fazer uso de gpt’s públicos sob risco de efetuar algum leak de dados sensíveis ou privados. Então como dei a volta ao problema? Simples, IA selfhosted!
Decidi portanto escrever este post sobre o tema, e como poderemos instalar e integrar um LLM como o Ollama2 no nosso homelab (mesmo sem a necessidade de GPU). Para além disto, iremos integrar o LLM DeepSeek-Coder (modelo de LLM para programação) ao Ollama2 e demonstrar como aceder e fazer solicitações diretamente do Visual Studio Code.

O que é o Ollama2?
Ollama2 é uma plataforma de LLM em ambientes self-hosted projetada para facilitar a implantação e a execução de modelos de machine learning em ambientes de produção. Ele oferece suporte a uma variedade de modelos de machine learning e pode ser facilmente integrado a pipelines de produção existentes.
Requisitos do Sistema
Antes de começarmos, certifiquem-se de que o vosso sistema tem os seguintes requisitos:
– Um servidor Linux (No meu caso Suse Tumbleweed – 2024 build).
– Processador com multi-core. GPU recomendado mas não obrigatório. Quanto mais cores/threads, mais rápida será a resposta.
– Um servidor docker para a componente de webui.
– Acesso de root ou permissões sudo.
– Conexão com a Internet (para descarregar modelos). Em funcionamento não necessita de acesso a internet.
Passo 1: Instalação do Ollama2
1. Abram uma sessão ssh no vosso servidor Linux.
2. Executem o script de instalação:
curl -fsSL https://ollama.com/install.sh | sh
3. Editar o systemd configuration file (Este é um exemplo. Adaptem as vossas necessidades)
[Unit] Description=Ollama Service After=network-online.target [Service] Environment="OLLAMA_HOST=0.0.0.0:11434" ExecStart=/usr/local/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=/sbin:/usr/sbin:/usr/local/sbin:/root/bin:/usr/local/bin:/usr/bin:/bin" [Install] WantedBy=default.target
Passo 2: Instalação de uma WebUI para o Ollama2
Assumindo que não se sentem á vontade para injectar comandos via curl, instalem uma Web-UI. Para tal, nada mais simples.
Para isso efetuar num docker server que tenham este comando:
# docker run -d -p 3001:8080 -e OLLAMA_BASE_URL=http://$ip_da_vossa_instancia:$porta_da_vossa_instancia \ -v /config/ollama-webui:/app/backend/data --name ollama2-webui - --restart always ghcr.io/open-webui/open-webui:main
- Via web-ui, escolham para o ollama2 descarregar um LLM (por exemplo o llama2) para funcionar. Isto é conseguido através do menu settings, que pode ser encontrado quando clicam no vosso username no canto inferior esquerdo:
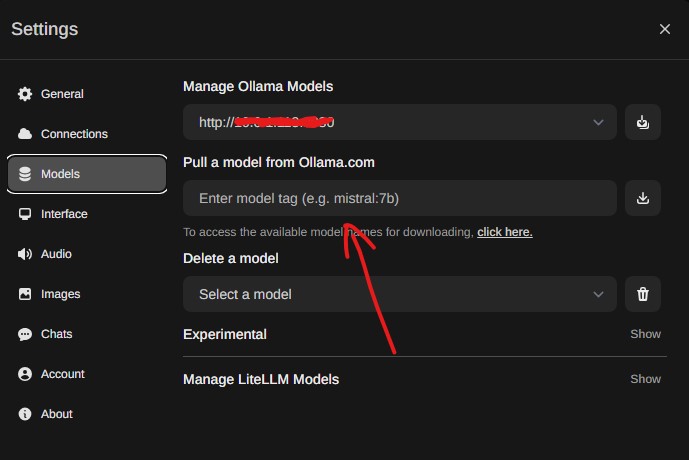
- Aguardem pois o modelo irá demorar algum tempo a ser descarregado.
- Experimentem 🙂
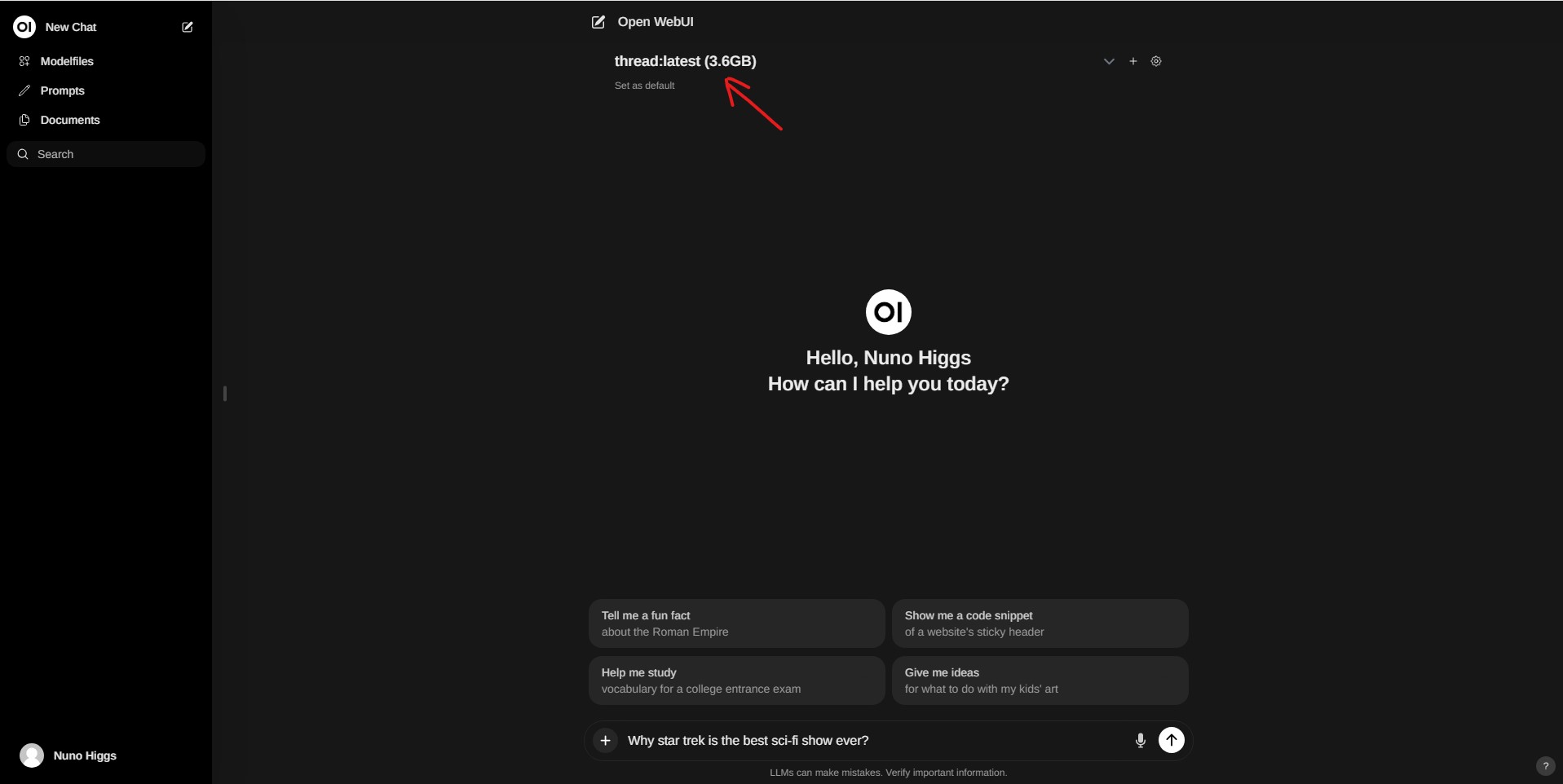
Nota: Na primeira imagem tem uma seta a apontar para o nome do modelo. Tem de ser o modelo LLM que descarregaram no ponto 5.
Passo 3: Integração com DeepSeek-Coder
O próximo passo é integrar o LLM DeepSeek-Coder ao vscode para aproveitar os recursos de coding avançados.
Para isto ir ao 1. acima demonstrado e adicionar o LLM DeepSeek-Coder.
Em seguida, no vscode, adicionar o seguinte plugin no visual studio code:

Após, configurar o mesmo carregando na roda dentada. Aqui iremos indicar o IP do nosso ollama2, o porto e o modelo LLM a ser executado:
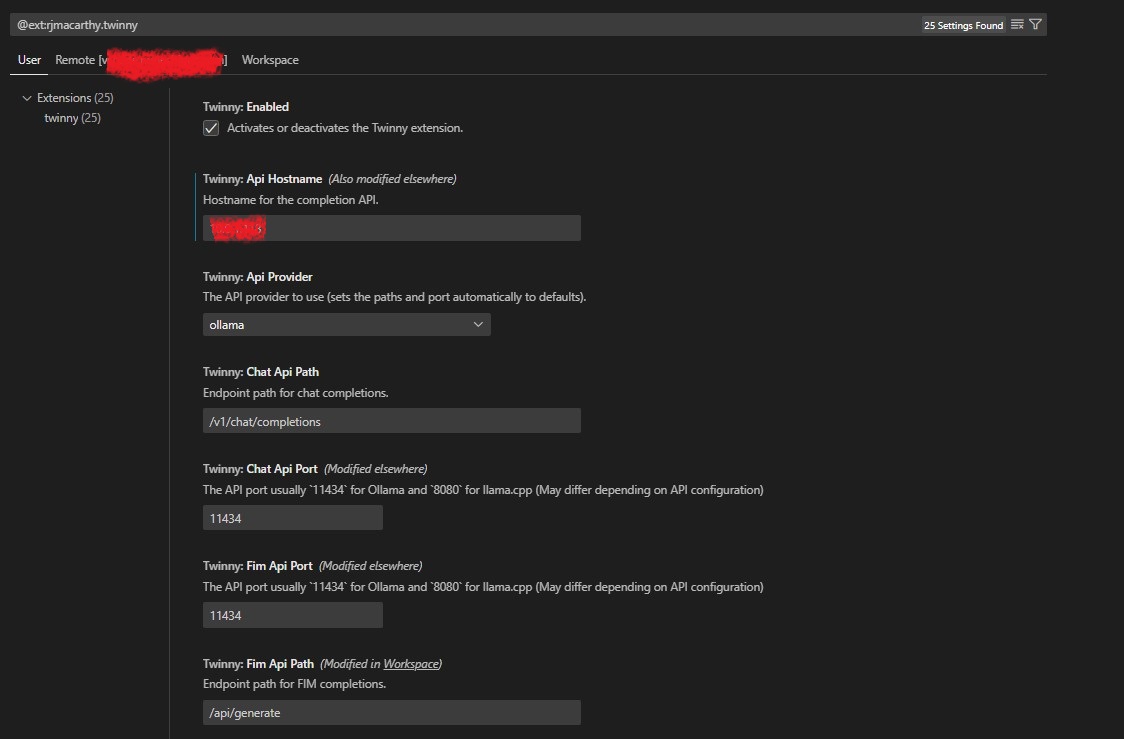
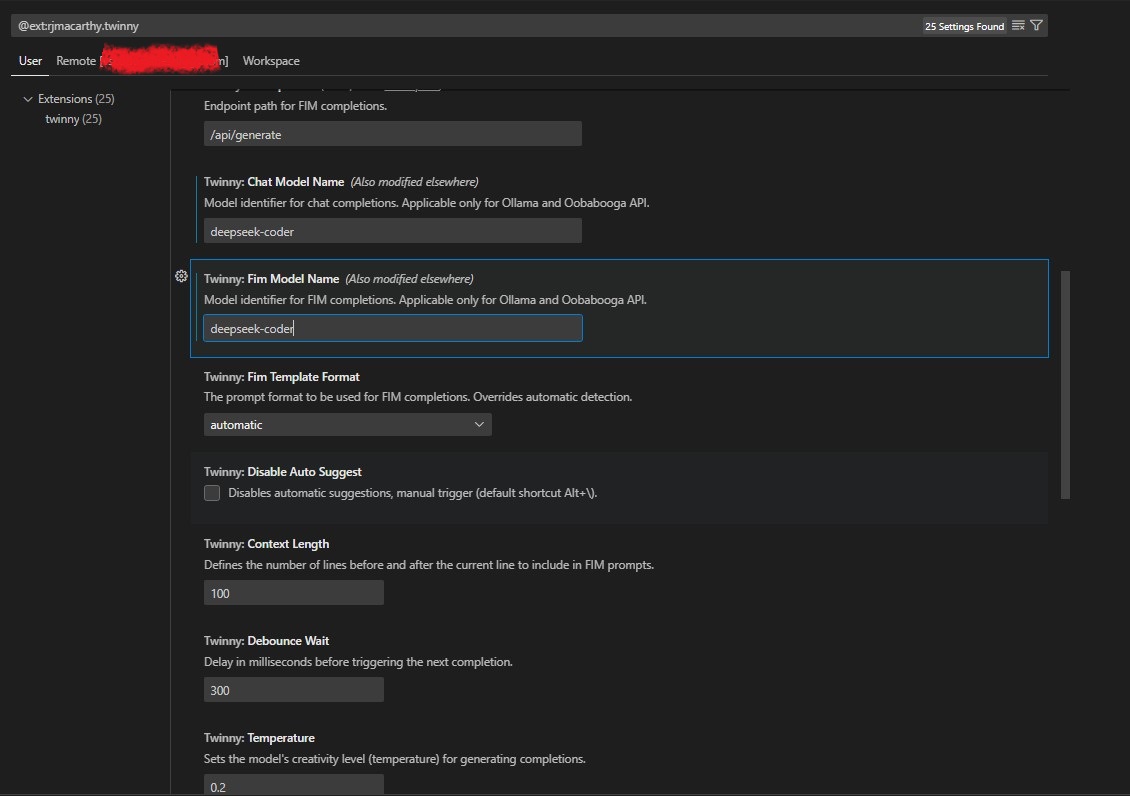
Nota: Validem nos três tab – user, remote e workspace que as vossas configurações estão correctas e conseguem chegar sem dificuldade ao ollama.
Se tudo estiver bem, deverá vos aparecer um icon do lado esquerdo na tab ao alto:

Carreguem nele e ponham as vossas questões de coding ao LLM (convêm ser em inglês, embora tenha notado que português até funciona de forma aceitável).
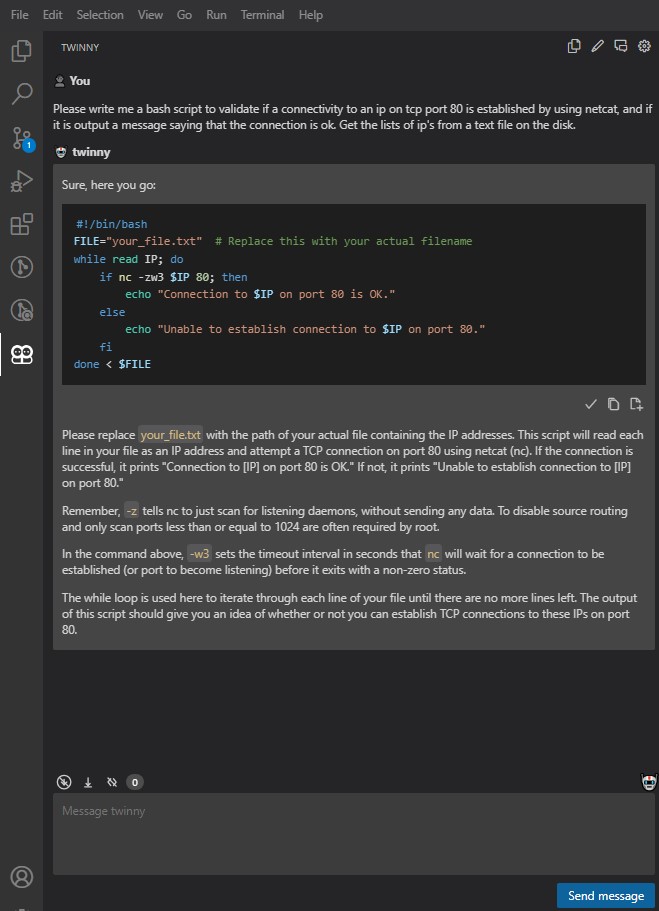
Fazendo a coisa um pouco mais difícil agora:
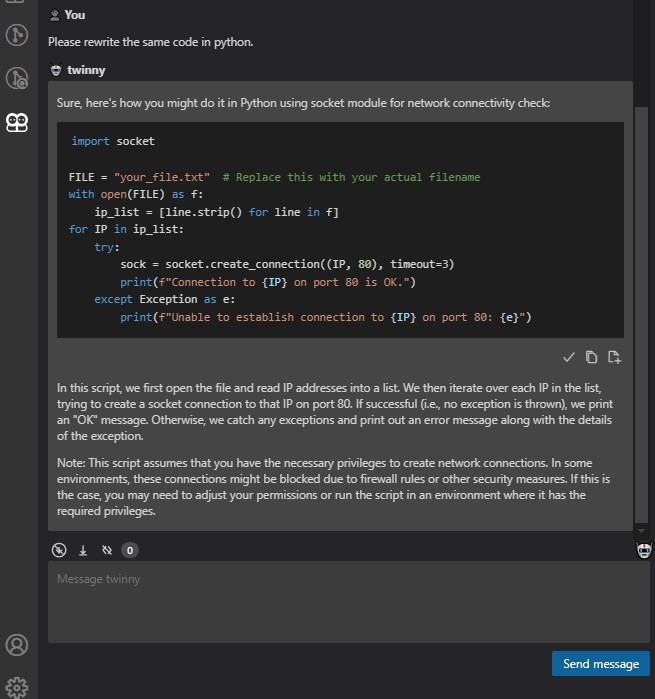
Isto é aplicável a praticamente a todas as linguagens que se lembrem. E não fica só por aqui. Pode e ajuda muito a despachar tarefas básicas de coding para nos podermos concentrar na parte importante da tarefa.
Finalmente, e para todos aqueles que irão correr modelos sem GPU’s podem aumentar a resposta do vosso processo, aumentando o numero de threads para o que julgarem necessário e até ao limite que o vosso computador permita:
No modelfiles (webui) carregar em modelfiles no canto superior direito:
Create a modelfile:
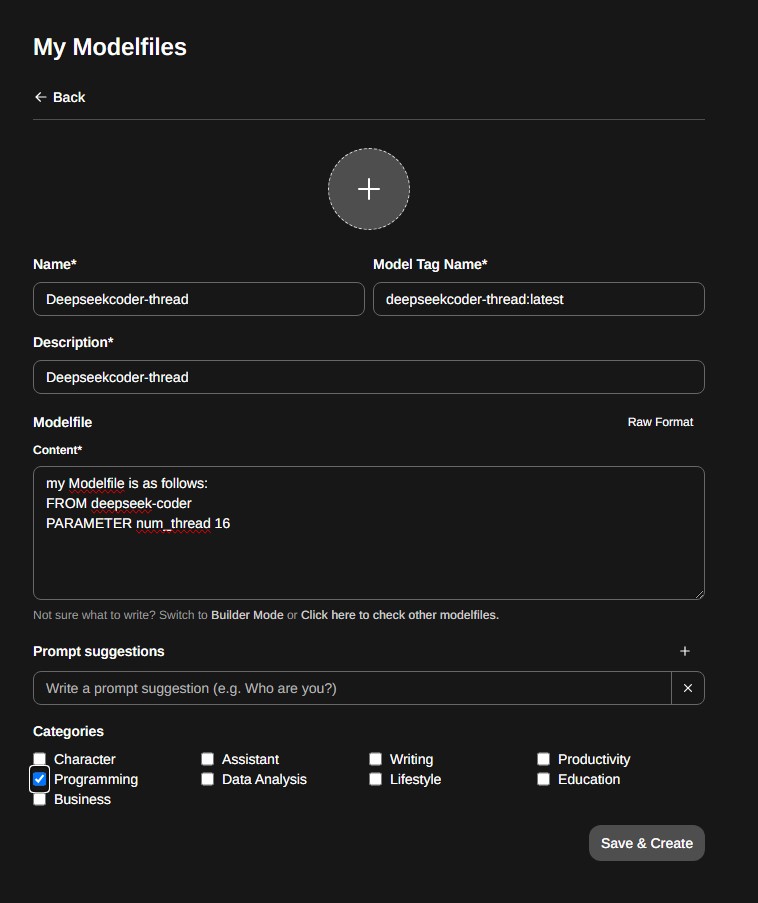
Preencher como abaixo. Notem que o que interessa aqui são os campos FROM deepseek-coder PARAMETER e num_thread 16. O primeiro diz qual o modelo que deve afinado, e o segundo o numero de cpu threads a usar. Neste caso, este servidor tem 64 cores/128 threads e como tal dei a possibilidade ao ollama de escalar o processamento a 16 dos seus cores.
Code snippet de exemplo:
my Modelfile is as follows: FROM deepseek-coder PARAMETER num_thread 16
Finalmente, no vosso vscode alterem para o novo modelo que acabaram de criar, neste caso o Deepseekcoder-thread. Não se esqueçam de alterar nas três tabs.
Conclusão.
Neste guia, exploramos como instalar e configurar o Ollama2 num servidor Linux, integrá-lo ao DeepSeek-Coder e fazer solicitações diretamente do Visual Studio Code. Com estas ferramentas na nossa mão, podemos facilmente implantar e executar modelos de machine learning em nossos próprios ambientes. Experimentem e adapte estas instruções conforme necessário para atender às vossas necessidades específicas.
No próximo post irei ensinar a integrar modelos de LLM que não são direct-ollama-downloadable como os que existem no huggingface e expandir o vosso universo de IA para um tamanho que nunca imaginaram.
Espero que tenham gostado deste post. Até a próxima semana e claro ja sabem que se notarem alguma coisa estranha, errada ou simplesmente absurda, sabem onde falar comigo.
Um abraço!
Nuno