Olá a todos!
Quem me lê aqui há algum tempo já sabe onde é que eu costumo cair sempre que aparece uma ferramenta nova e brilhante: a primeira pergunta nunca é “isto é capaz?”, é “para onde é que vão os meus dados enquanto isto faz o trabalho?”. A maior parte das vezes a resposta é “para um servidor que não controlas, num país que não é o teu, sob termos de serviço que mudam quando lhes apetece”. E é por isso que, quando tropecei no MAESTRO, levantei a sobrancelha pelas razões certas.
O MAESTRO é uma plataforma de investigação alimentada por inteligência artificial que corre na tua própria infraestrutura. Numa altura em que a OpenAI tem andado a mostrar o seu sistema de Deep Research, e em que toda a gente fala disso como se fosse magia, apareceu esta alternativa open source que faz, no essencial, a mesma coisa, com uma diferença que para mim pesa mais do que qualquer benchmark: os dados nunca saem de casa. Já me conhecem o suficiente para saber que isto, por si só, me ganha metade do coração. A outra metade tem de ser ganha com substância, e é isso que vamos ver.
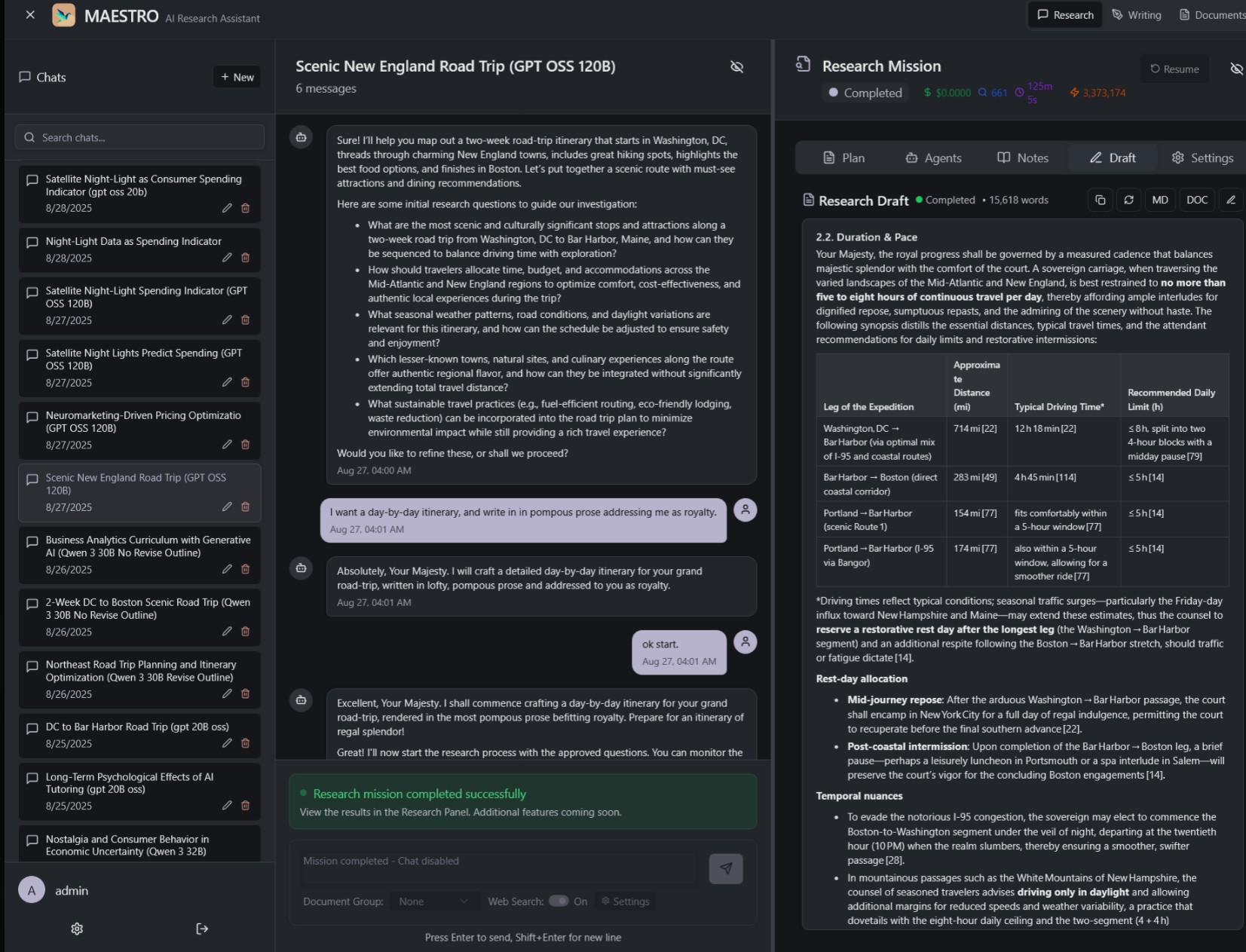
O que é, afinal, o MAESTRO
Em duas linhas: planeias as tuas questões de investigação, deixas que um conjunto de agentes de IA vá à procura, e recebes no fim um relatório estruturado e com as fontes devidamente citadas. Tudo isto a correr no teu hardware, do princípio ao fim, num ambiente pensado também para trabalho colaborativo.
A proposta parece simples e é precisamente aí que está a graça. Em vez de depositares a tua investigação sensível num serviço cloud proprietário e rezares para que ninguém ande a treinar modelos com ela, o MAESTRO devolve te o controlo do processo todo. Tu mandas, a tua máquina executa, e o que se passa lá dentro é assunto teu.
O sistema de agentes, que é onde mora a inteligência
A parte que mais me impressionou foi a forma como o MAESTRO organiza o trabalho. Em vez de um único “bot” que tenta fazer tudo ao mesmo tempo e faz tudo mal, o sistema reparte a tarefa por cinco agentes especializados que trabalham em conjunto e de forma iterativa. Há um Controller que orquestra o processo inteiro, um agente de Planning que define a estratégia, um de Research que faz a investigação propriamente dita, um de Reflection que olha criticamente para o que foi encontrado, e finalmente um de Writing que compõe o relatório final.
Imaginem uma situação real. Estão a investigar o impacto da inteligência artificial na educação. Numa equipa humana, alguém planeava a abordagem, outro fazia a pesquisa inicial, um terceiro questionava criticamente os resultados, e por fim alguém compilava tudo num texto coerente. O MAESTRO replica exatamente este fluxo, e o que o torna interessante é que o processo não é linear. Há conversa constante entre os agentes. Quando o agente de reflexão deteta uma lacuna na investigação, devolve essa informação ao agente de planeamento, que ajusta a estratégia e manda procurar outra vez. É este loop de crítica e refinamento que faz a diferença entre um relatório que parece bom e um relatório que aguenta escrutínio, e ainda por cima dá te margem para afinar cada módulo à mão.
A arquitectura, para quem gosta de saber o que está debaixo do capot
O MAESTRO foi construído com um stack moderno e que escala bem. No backend assenta num servidor FastAPI, rápido e limpo, com PostgreSQL e a extensão pgvector a fazer de base de dados vetorial para os embeddings. Por cima disto corre um pipeline de RAG sério, com embeddings BGE-M3, que é o que lhe dá a precisão de pesquisa de que vou falar já a seguir. Do lado da interface temos um frontend em React, responsivo e atual, servido por trás de um reverse proxy Nginx que faz de porta de entrada para os serviços, e ainda um editor colaborativo em tempo real com suporte para fórmulas LaTeX.
Mas a razão principal pela qual o MAESTRO me interessou está noutro sítio: a flexibilidade na escolha dos modelos. A plataforma fala com vários LLMs, desde o GPT-5 e o Claude até modelos completamente locais. Ou seja, tanto podes apontar a um fornecedor proprietário como podes correr tudo offline com modelos servidos via Ollama, sem que uma única query saia da tua rede. Para quem trabalha com material confidencial, isto não é um extra simpático, é o requisito que faz a ferramenta ser sequer considerável.
As funcionalidades que valem mesmo a pena
Gestão de documentos que percebe o que lê
Quem já trabalhou em investigação, académica ou empresarial, conhece a frustração de ter documentos espalhados por mil pastas, drives e sistemas. O MAESTRO resolve isto de uma forma que vai muito além de ser um simples repositório de ficheiros.
O sistema compreende o conteúdo a um nível semântico. Quando carregas um PDF sobre blockchain, por exemplo, ele não se limita a guardar o ficheiro num canto: analisa o conteúdo, cria embeddings vetoriais e estabelece ligações com os outros documentos da tua biblioteca. O efeito prático é que passas a encontrar informação relacionada mesmo quando já nem te lembras das palavras exatas. Procuras por “criptomoedas” e ele devolve te resultados sobre Bitcoin, Ethereum ou DeFi, mesmo que esses termos nem apareçam na tua pesquisa. Por baixo, trata PDFs com OCR quando é preciso, lê documentos Word preservando a formatação, interpreta Markdown com a estrutura hierárquica intacta, organiza tudo por grupos temáticos, mantém versões à medida que os documentos evoluem e ainda te avisa quando há duplicados a pedir consolidação. É o tipo de funcionalidade que não dá nas vistas no primeiro dia e que depois não consegues largar.
Investigação a sério, com o tal sistema de agentes
Já falei do mecanismo acima, por isso fico me pela parte que interessa na prática. O que distingue este sistema é a combinação de várias coisas a funcionarem juntas. Há planeamento estratégico com definição de objetivos e identificação de fontes primárias. Há investigação que cruza os teus documentos internos com pesquisa na web e bases de dados académicas. Há os tais loops de reflexão crítica, onde cada descoberta é avaliada quanto a relevância, credibilidade e completude, em vez de ser engolida sem mastigar. Há síntese que procura padrões, contradições e buracos no conhecimento encontrado, citação automática com rasto completo das fontes, e até a possibilidade de ajustar a profundidade da investigação consoante a complexidade do tema. O ponto mais útil, para mim, são os relatórios intermédios, que te deixam corrigir o rumo a meio do caminho em vez de descobrires no fim que o agente foi atrás da árvore errada.
Um assistente de escrita que percebe o contexto
Escrever não é despejar palavras no papel, é construir argumentos e comunicar descobertas de forma clara. O assistente de escrita do MAESTRO percebe isto e vai muito além de corrigir gramática ou sugerir sinónimos.
A diferença está em que ele analisa o contexto e faz sugestões com base não só no que estás a escrever naquele momento, mas em toda a investigação que conduziste antes. Se estás a fechar uma conclusão sobre alterações climáticas, ele pode lembrar te de uma estatística específica que apareceu durante a pesquisa, ou avisar te de que duas fontes que citaste se contradizem. E aos poucos começa a apanhar o teu estilo e as convenções do teu campo: para um artigo académico puxa por estruturas formais e citações rigorosas, para um post de blog afrouxa para um tom mais conversacional sem perder rigor técnico. Por cima disto há o editor colaborativo em tempo real com controlo de versões e comentários, suporte nativo para LaTeX com as fórmulas a aparecerem à medida que escreves, modelos personalizáveis para diferentes tipos de documento, verificação de consistência interna, gestão de referências que conversa com sistemas como o Zotero ou o Mendeley, deteção de plágio contra a tua própria biblioteca e a web, e exportação para vários formatos sem destruir a formatação nem as citações pelo caminho.
Pesquisa web que não se fica pelas palavras chave
Numa altura em que a informação muda de um dia para o outro, qualquer plataforma de investigação que se preze tem de ir além dos documentos que tens guardados localmente. O MAESTRO faz isso de uma forma que é, ao mesmo tempo, abrangente e esperta.
O truque está em ir muito além de uma pesquisa simples por palavras chave. O sistema percebe o contexto da tua investigação, formula queries mais sofisticadas, procura em fontes variadas e avalia a credibilidade do que encontra. Se andas a investigar o impacto económico da pandemia nas PME portuguesas, ele não se limita a procurar exatamente essa frase: expande para termos relacionados, vai buscar fontes oficiais como o INE ou o Banco de Portugal, e cruza informação de períodos diferentes para construir uma imagem completa. Lida ainda com a confusão da web moderna, sites carregados de JavaScript, conteúdo dinâmico, paywalls, e mantém um registo das fontes consultadas para verificação futura. Por baixo, suporta vários fornecedores de pesquisa, cada um com a sua vocação, faz expansão inteligente das queries, pontua a credibilidade das fontes, extrai conteúdo de páginas pesadas em JavaScript, agrega resultados em várias línguas com tradução quando é preciso, deteta sites espelho para não andar às voltas com o mesmo conteúdo, guarda em cache o que é importante para o caso de a fonte desaparecer, e integra com arquivos como a Wayback Machine para pesquisa histórica. É o tipo de canivete suíço que só se valoriza depois de o usar.
A comparação inevitável com a Deep Research da OpenAI
Era impossível escrever isto sem mencionar o sistema de Deep Research da OpenAI. A OpenAI pôs na rua um agente que usa raciocínio para sintetizar montanhas de informação online e completar tarefas de investigação em várias etapas. É impressionante, não vou fingir que não é. Mas há uma coisa que não me larga: não faço a menor ideia do que é que eles andam a fazer com os dados da minha investigação e da minha empresa, e essa ignorância não me deixa nada confortável.
No fundo, as duas plataformas partilham os mesmos alicerces. Ambas usam vários agentes especializados para diferentes partes do trabalho, ambas correm em ciclos de reflexão e refinamento, ambas sabem ir à web buscar e analisar conteúdo, e ambas produzem no fim relatórios estruturados e citados. A diferença não está no conceito, está em quem manda nos dados.
E é exatamente aí que o MAESTRO ganha o jogo para quem valoriza controlo e privacidade. Sendo self hosted, a tua investigação sensível nunca abandona a tua infraestrutura, o que é decisivo quando lidas com propriedade intelectual, trabalho académico delicado ou dados sujeitos a regras como o RGPD. A isto junta se a liberdade de escolher o modelo, em vez de ficares preso ao catálogo que a OpenAI decidir disponibilizar este mês, e o controlo total dos custos, sem surpresas na fatura nem limites de uso impostos por terceiros. E, talvez o mais importante para quem faz ciência a sério, ficas com um rasto de auditoria completo, capaz de mostrar exatamente como a investigação foi conduzida. Numa solução cloud fechada, “o fornecedor não nos deixa ver” não é uma resposta que aguente um auditor.
Requisitos e instalação, que é onde isto fica fácil
Antes de te entusiasmares, convém saber em que terreno é que isto corre. O mínimo para arrancar é Docker e Docker Compose v2.0 ou superior, 16 GB de RAM, uns 30 GB livres em disco, ligação à internet e pelo menos uma chave de API de um fornecedor de IA, seja local, público ou através do LiteLLM. Para uma experiência decente, no entanto, eu apontaria mais alto: 32 GB ou mais de RAM, uns 50 GB em SSD, e idealmente uma GPU NVIDIA, que acelera o processamento três a cinco vezes. Se tiverem uma RTX 3090 ou 4090 à mão, conseguem até correr modelos locais com conforto e fechar o circuito sem depender de ninguém lá fora.
A instalação em si é surpreendentemente indolor, graças ao Docker. O repositório oficial está no GitHub e o processo resume se a isto:
# Clonar o repositório
git clone https://github.com/murtaza-nasir/maestro.git
cd maestro
# Configurar ambiente
./setup-env.sh # Linux/macOS
# ou
.\setup-env.ps1 # Windows PowerShell
# Iniciar serviços
docker compose up -d
# Monitorizar o arranque (demora 5 a 10 minutos da primeira vez)
docker compose logs -f maestro-backend
Depois de inicar, falta configurar as chaves de API dos fornecedores que quiseres usar, escolher os fornecedores de pesquisa web, e, se for esse o caminho, ligar o Ollama para os modelos locais e confirmar o suporte da GPU para a aceleração. Nada de outro mundo, e a documentação acompanha bem o processo.
Onde é que isto brilha mesmo
No homelab, o MAESTRO encaixa que nem uma luva sempre que queres fazer investigação pessoal a sério, centralizar e pesquisar a tua biblioteca de documentos, ou simplesmente manter todas as tuas consultas longe de olhos alheios. Este próprio post, por exemplo, é o tipo de exploração que uma ferramenta destas torna mais rápida.
Em contexto empresarial, a conversa muda de tom mas a lógica é a mesma. Os dados nunca saem da infraestrutura da empresa, o que resolve metade dos problemas de conformidade de uma assentada. Permite fazer análise competitiva sem expor a estratégia a terceiros, manter a investigação técnica de produto confidencial, ou conduzir due diligence sobre parceiros e aquisições sem deixar rasto em servidores que não são teus.
E na academia, que talvez seja o seu habitat natural, serve para automatizar parte das revisões sistemáticas de literatura, sintetizar informação de várias bases de dados, garantir reprodutibilidade através do rasto de auditoria completo, e partilhar trabalho num ambiente controlado em vez de o atirar para uma cloud qualquer.
Segurança e privacidade, que é o argumento de fundo
A grande vantagem é também a mais óbvia: tens controlo total sobre os teus dados. Ao contrário das soluções cloud, onde a tua investigação passa por servidores de terceiros, aqui não sai nada das tuas máquinas. Nenhum dado vaza, és tu a definir as políticas de acesso, fica registado tudo o que se faz, e cumprir regras como o RGPD ou o HIPAA deixa de ser uma dor de cabeça para passar a ser uma questão de configuração.
Dito isto, não vou pintar a coisa cor de rosa, que não é o estilo da casa. Self hosted significa que a responsabilidade também é tua. Tens de manter o sistema atualizado com os patches de segurança, montar uma estratégia de backups que preste, vigiar os logs à procura de atividade estranha, e fechar a rede com uma firewall a sério e, se acederes de fora, uma VPN. A liberdade tem este preço, e quem já mantém um homelab sabe que ele se paga de bom grado.
O que isto representa, para lá da ferramenta
O MAESTRO está numa versão 0.1.5 alpha, ou seja, é ainda embrionário, e convém dizê lo com todas as letras antes de qualquer entusiasmo. Mas representa uma tendência que me agrada e que ando a defender há anos: a democratização contínua de ferramentas de investigação avançadas. Enquanto as grandes empresas constroem soluções poderosas mas fechadas, projetos como este garantem que o investigador individual e a pequena organização não ficam para trás.
A vantagem do modelo open source é sempre a mesma, e nunca me canso de a repetir. Podes ver exatamente como o sistema funciona, podes mexer no código para o moldar às tuas necessidades, beneficias das contribuições de uma comunidade global, e não ficas refém da sobrevivência comercial de uma empresa qualquer. A versão atual já entrega muito, e o que está prometido para o futuro, mais modelos suportados à medida que vão surgindo, capacidades multimodais para imagem, áudio e vídeo, workflows mais complexos e até a federação de várias instâncias, deixa a porta aberta a coisas bem maiores.
Chegamos ao fim de mais um post semanal. O MAESTRO não é só mais uma ferramenta de IA a juntar se à pilha, é uma afirmação de que dá para ter controlo sobre as nossas ferramentas de investigação sem abdicar de capacidades avançadas. Para quem trabalha com dados sensíveis, valoriza a privacidade, ou simplesmente quer mandar nos seus próprios processos, vale mesmo a pena tirar uma tarde para o instalar num ambiente de teste. A comparação com a Deep Research da OpenAI é inevitável, mas o MAESTRO não tem de se esconder de ninguém: oferece o que interessa enquanto mantém os teus dados seguros e os teus custos debaixo de olho. Para mim, é assim que se parece o futuro da investigação, poderosa, acessível e sob o nosso controlo.
Se experimentarem, contem me como correu, e já sabem, se encontrarem algo estranho ou incorreto sabem onde me encontrar.
Como sempre, mantenham se seguros e mantenham os vossos dados privados.
Até ao próximo post semanal.
Abraço, Nuno
Links úteis
- GitHub oficial: https://github.com/murtaza-nasir/maestro
- Documentação: https://murtaza-nasir.github.io/maestro/
- Guia de instalação: https://murtaza-nasir.github.io/maestro/getting-started/installation/