Olá a todos,
Como certamente sabem, um dos componentes fundamentais do meu datacenter são os backups.
Recentemente, e devido ao que tenho andado a testar, o volume de dados diários a que faço backup chegou aos 40GB.
Embora o valor não seja nada perto de um volume empresarial/corporativo, imaginem-se a ter que fazer backups (sim perder os dados não é uma opção, da mesma forma que raid não é backup) a 40 GB dos vossos dados de casa (ie projetos, fotos, documentos, etc).
A NAS para onde os backups estão a ser feitos – de 4TB – estava a ter de ter o seu espaço reciclado de 3 em 3 meses.
Tendo em conta que por norma faço por ter retenção de backups de 1 ano, foi me colocado o desafio: Ou comprava uma NAS nova com mais capacidade, ou procurava uma solução que acomodasse a minha necessidade de espaço para o tempo que necessito.
Mais ou menos na mesma altura, e enquanto procurava por uma alternativa que me sanasse esta necessidade, descobri no reddit/r/homelab (where else) uma thread que falava de um fork alternativo ao bacula – de alguém que saiu do projeto original – de nome bareos.
![]()
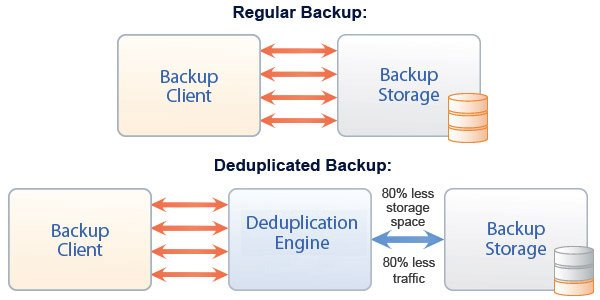
O bareos alem de toda a panóplia de coisas que o bacula já fazia com muito sucesso, introduziu em domínio publico (no bacula só está disponível para clientes enterprise), o conceito de de-duplicação.
E eis que chegamos ao nosso post semanal. De-duplicação para as massas!
Era mesmo o que eu necessitava.
Faria um base backup (com retenção anual), e em seguida todos os backups que utilizassem esse job, passariam a o utilizar como template inicial fazendo de-duplicação dos dados já copiados inicialmente.
A diferença entre este tipo de backup para um backup diferencial, é que num backup diferencial, é feito backups a ficheiros que mudaram num dito job enquanto neste, os ficheiros idênticos entre vários jobs não sofrem backup.
O resultado seria uma GRANDE diminuição ao que era feito backup e consequentemente a quantidade que era armazenada.
Procurando no google temos a seguinte descrição sobre de-duplicação:
“In computing, data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. Related and somewhat synonymous terms are intelligent (data) compression and single-instance (data) storage”
Ou seja, enquanto num backup típico todos os ficheiros são copiados.
Mesmo que os ficheiros sejam idênticos aos que foram copiados nos últimos 300 backups.
Com de-duplicação, o agente irá observar cada ficheiro, validar se já existe em outro backup válido, e em seguida decidir se irá ou não fazer a copia.
Com isto, poupa-se tempo de copia, IO de disco, e espaço ocupado.
Não existe no entanto bela-sem-senão: Embora a de-duplicação seja hoje um termo house hold, existem ainda riscos e custos escondidos no conceito:
Se por exemplo o base backup ficar corrompido, as imagens construidas desde este serão inválidas tornando impossível um restore.
Mesma coisa para o custo de processamento. Embora exista poupança no espaço ocupado e tráfego de rede, irá exigir mais do processador (e consequente consumo em operações de cloud ou em eletricidade), para calcular o que deve ou não ser copiado.
Este conceito é muito usado em ambientes corporativos (por exemplo EMC DataDomain, Symantec Netbackup), com bastante certeza e segurança.
Para a minha escala, o procedimento para o bacula/bareos é relativamente simples.
Iremos necessitar de um base job (o job que irá conter o backup original e que irá servir como template:
# Definição de job template
Job {
Name = “xVpar“
JobDefs = “xVpar-base”
Schedule = base
Level = Base
Client = <base-machine-hostname>-fd
}
Um job de backup normal que depende do Job Template
Job {
Name = “<bareos-client-hostname>-daily-schedule”
JobDefs = “xVpar-dedupe“
Client = <bareos-client-hostname>-fd
Base = <base os backup> (no nosso caso xVpar)
Write Bootstrap = “/var/spool/bareos/<bareos-client-hostname>.bsr”
}
Um schedule diário de backups com a definição de “Accurate” ativa.
Está é a flag para que o backup seja validado contra o base job.
A flag Spool Atributes é colocada para que em caso de falha de backup, indicação dos ficheiros que não foram carregados não vá parar a tabela de mysql que serve de backend ao engine do bareos.
JobDefs {
Name = “xVpar-dedupe“
Type = Backup
Level = Incremental
Client = <bareos-client-hostname>-fd
FileSet = “fs-linux”
Schedule = “daily-schedule”
Storage = NAS03
Messages = Daemon
Pool = daily-schedule
Priority = 10
Max Run Time = 360 minutes
Accurate = yes
Spool Attributes = yes
}
Finalmente a definição do base job.
Acaba por ser praticamente idêntico ao diferencial, sendo apenas que o nível de backups são “base”.
De notar que mantenho transversalmente os spool atributes em todas as definições de jobs:
JobDefs {
Name = “xVpar-base”
Type = Backup
Level = Base
Client = <bareos-client-hostname>-fd
FileSet = “fs-linux”
Schedule = “base”
Storage = NAS03
Messages = Daemon
Pool = base
Priority = 9
Max Run Time = 600 minutes
Accurate = yes
Spool Attributes = yes }
Finalmente, podemos mostrar o output de resultado do nosso backup:
1-Mai 16:12 bareos-dir JobId 5422: Using Device “NAS03-0” to write.
1-Mai 16:12 bareos-dir JobId 5422: Using BaseJobId(s): 1
1-Mai 16:12 bareos-dir JobId 5422: Sending Accurate information to the FD.
No fim do backup:
1-Mai 18:10 bareos-fd JobId 5422: Space saved with Base jobs: 3692 MB
Como é bem visível num backup simples foram poupados 3.6GB (sensivelmente 87% do total de backup sem de-duplicação).
Esta alteração permitiu numa fase inicial baixar o meu consumo de storage do NAS em 30%. Calculo que até ao fim do processo consiga poupar perto de 70%, conseguindo o meu objetivo de manter a arquitetura de hardware que possuo no momento mais tempo.
Experimentem com o conceito. Vão ver que vale a pena.
Caso tenham alguma duvida já sabem onde me encontrar.
Abraço!
Nuno Higgs