Bom dia a todos,
Desde o ultimo post sobre ElasticSearch, chegou a a altura de fazer um post sobre um tema que tem vindo a ser pedido repetidamente: Hadoop.
É uma solução/framework de que permite o armazenamento de Big Data num ambiente distribuído, de forma a que possa ser processado paralelamente.
Com o selo de qualidade da Apache Foundation, é algo que está em high demand no mercado nacional e internacional.
Sei que existem colegas interessados na tecnologia, pela buzzword, em testar o que é, para que serve, como funciona e como poderei o integrar nos TI/SI da minha empresa.
![]()
Em primeiro caso é importante saber o que é, e o que não é o Hadoop:
O Apache Hadoop é uma framework de software que permite correr processos distribuídos em grandes datasets, através de farms computacionais usando apenas modelos de programação simples.
É pensado e desenhado para escalar de um ou dois servidores para milhares de máquinas, conseguindo assim utilizar os recursos computacionais e de storage.
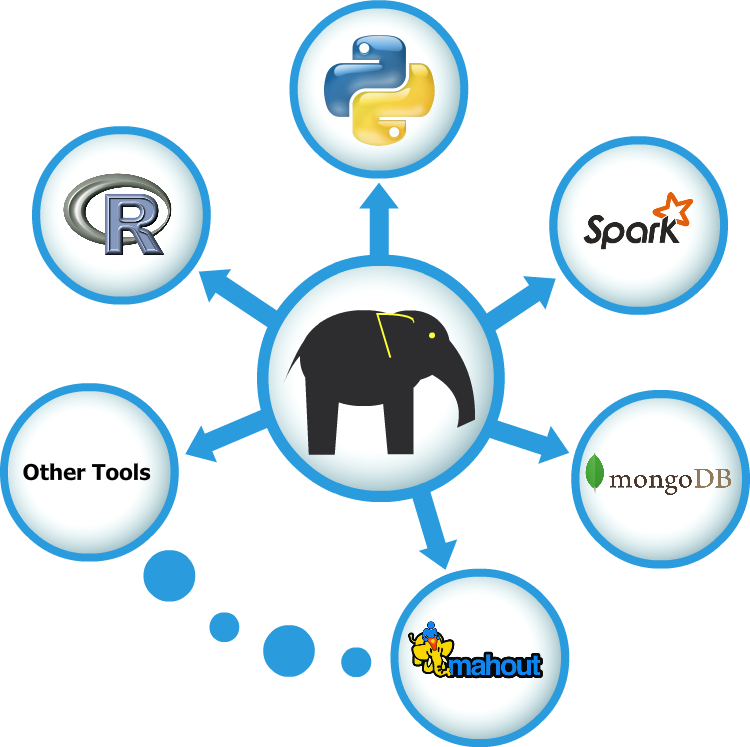
Existem casos específicos onde o Hadoop brilha, por exemplo na escalabilidade (hoje termos uma BigData de 2TB e daqui a 10 anos de 2000PB sem alteração do paradigma), frameworks extremamente diversificadas (mongoDB, spark, mahout, etc) e disponibilidade de dados pela sua natureza distribuída.
Contudo existem downsides:
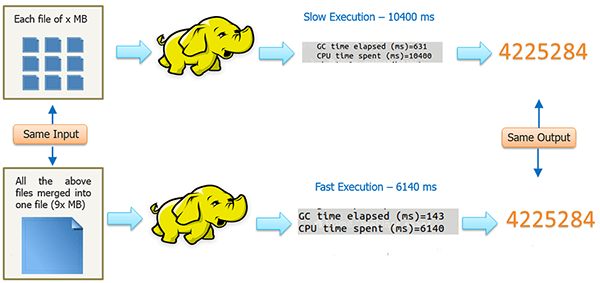
O Hadoop por ter no seu core uma framework de batch não poderá ser utilizada para obter dados em tempo real (ou near real time), é muito susceptível de sofrer lentidão em casos em que a informação se encontre fragmentada (por exemplo 1024 ficheiros de 1TB versus 1 ficheiro de 1PB), e não é de forma alguma um substituto para a tradicional data warehouse.
Igualmente em casos onde a segurança dos dados seja importante, existem componentes extras como o Apache Accumulo que podem ser integradas em Hadoop de forma a garantir um nível desejado de criptografia e segurança.
Existe um artigo muito completo sobre o tema e os use cases que pode ser consultado aqui.
No final do dia, o Hadoop serve para armazenar, e depurar dados através de Map Reduce até se conseguirem dados úteis, desde instancias de big data, e apresentar os resultados de forma concisa, e simples.
Faz parte de um ecosistemas aplicacional que envolve desde a tecnologia de map reduce, managment, coordination, scheduling, noSQL DB, scripting, machine learning, etc.

As componentes principais do Hadoop são o Yarn (batch processing) e o HDFS (storage). Este post é referente ao componente de storage. Se quiserem ler mais sobre a componente do Yarn (batch) a IBM tem um artigo muito profundo aqui.
E agora, depois de uma introdução anormalmente grande, iremos implementar o nosso lab 🙂
Para o nosso caso iremos ter dois slave nodes (que processam) e um master (coordinator):
lxcHadoopMaster RUNNING 10.0.1.50 - NO lxcHadoopSlave01 RUNNING 10.0.1.51 - NO lxcHadoopSlave02 RUNNING 10.0.1.52 - NO
Em primeiro lugar será necessário garantir os pré requisitos necessários que são os seguintes:
Instalar java. As versões suportadas podem ser consultadas aqui. # curl -LO -H "Cookie: oraclelicense=accept-securebackup-cookie" “http://download.oracle.com/otn-pub/java/jdk/8u162-b14/jdk-8u162-linux-x64.rpm”
# yum localinstall jdk-8u162-linux-x64.rpm
# java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
Criar um utilizador aplicacional onde a solução será executada.
# useradd hadoop # passwd hadoop Changing password for user hadoop. New password: Retype new password: passwd: all authentication tokens updated successfully.
Adicionar FQDN mapping (ou configurar DNS para o efeito).
# vi /etc/hosts 10.0.1.50 lxchadoopmaster 10.0.1.51 lxchadoopslave01 10.0.1.52 lxchadoopslave02
Gerar chaves privadas para gerir os scripts remotos de Hadoop.
Nota: embora não seja necessário para os nós comunicarem uns com os outros, irá ser de grande utilidade na gestão do nosso cluster.
# su - hadoop $ ssh-keygen -t rsa $ ssh-copy-id -I ~/.ssh/id_rsa.pub hadoop@lxchadoopmaster $ ssh-copy-id -I ~/.ssh/id_rsa.pub hadoop@lxchadoopslave01 $ ssh-copy-id -I ~/.ssh/id_rsa.pub hadoop@lxchadoopslave02 $ chmod 0600 ~/.ssh/authorized_keys
Adicionar software de sistema que irá ser necessário mais a frente:
# yum -y install wget rsync which
Descarregar o software aplicacional em si e instalar ele na sua diretoria:
mkdir -p /opt/hadoop chown hadoop:hadoop /opt/hadoop su - hadoop cd /opt/hadoop wget http://www-us.apache.org/dist/hadoop/common/stable/hadoop-2.9.0.tar.gz tar xzf hadoop-2.9.0.tar.gz
Em seguida será necessário configurar as variáveis de ambiente para o utilizador aplicacional que irá executar a solução:
export HADOOP_HOME=/opt/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Recomendo que as variáveis sejam carregadas no bashrc ou no profile do utilizador.
Em seguida, editar o ficheiro $HADOOP_HOME/etc/hadoop/hadoop-env.sh e o JAVA_HOME conforme configurado nos vossos sistemas:
export JAVA_HOME=/usr/java/jdk1.8.0_162/jre/ export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
Finalmente chegou a altura de configurar o nosso Hadoop.
cd $HADOOP_HOME/etc/hadoop
Editar o ficheiro core-site.xml
# vi core-site.xml
# Adicionar dentro da tag configuration
<property>
<name>fs.default.name</name>
<value>hdfs://lxchadoopmaster:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
Editar o ficheiro hdfs-site.xml
# vi hdfs-site.xml # Adicionar dentro da tag configuration <property> <name>dfs.data.dir</name> <value>/opt/hadoop/dfs/name/data</value> <final>true</final> </property> <property> <name>dfs.name.dir</name> <value>/opt/hadoop/dfs/name</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
Editar (ou criar o ficheiro – depende da versão de Hadoop que estejam a instalar) mapred-site.xml
# vi mapred-site.xml
# Adicionar dentro da tag configuration
<property>
<name>mapred.job.tracker</name>
<value>lxchadoopslave01:9001</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>lxchadoopslave02:9001</value>
</property>
Enviar a nossa configuração para todos os nós da solução:
# su - hadoop $ rsync -auvx $HADOOP_HOME lxchadoopslave01:/opt/ $ rsync -auvx $HADOOP_HOME lxchadoopslave02:/opt/
Configurações especificas do Master Node:
# su - hadoop $ cd $HADOOP_HOME/etc/hadoop $ vi slaves lxchadoopslave1 lxchadoopslave2
Em seguida inicializar o name node no master:
# su - hadoop $hadoop namenode -format
O resultado será algo como:
[hadoop@lxcHadoopMaster ~]$ hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 18/02/20 12:32:57 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = lxchadoopmaster/10.0.1.50 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.9.0 STARTUP_MSG: classpath = /opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/hadoop/share/hadoop/common/lib/commons-net-3.1.jar:/opt/hadoop/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/opt/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/opt/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/hadoop/share/hadoop/common/lib/woodstox-core-5.0.3.jar:/opt/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/opt/hadoop/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/hadoop/share/hadoop/common/lib/stax2-api-3.1.4.jar:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar:/opt/hadoop/share/hadoop/common/lib/xz-1.0.jar:/opt/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/share/hadoop/common/lib/hadoop-auth-2.9.0.jar:/opt/hadoop/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/hadoop/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/hadoop/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/hadoop/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/hadoop/share/hadoop/common/lib/commons-io-2.4.jar:/opt/hadoop/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/hadoop/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/hadoop/share/hadoop/common/lib/json-smart-1.1.1.jar:/opt/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/hadoop/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/hadoop/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/hadoop/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/hadoop/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/hadoop/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/opt/hadoop/share/hadoop/common/lib/jcip-annotations-1.0.jar:/opt/hadoop/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/hadoop/share/hadoop/common/lib/activation-1.1.jar:/opt/hadoop/share/hadoop/common/lib/jsch-0.1.54.jar:/opt/hadoop/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/hadoop/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/hadoop/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/hadoop/share/hadoop/common/lib/junit-4.11.jar:/opt/hadoop/share/hadoop/common/lib/hadoop-annotations-2.9.0.jar:/opt/hadoop/share/hadoop/common/lib/slf4j-api-1.7.25.jar:/opt/hadoop/share/hadoop/common/lib/httpcore-4.4.4.jar:/opt/hadoop/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/hadoop/share/hadoop/common/lib/commons-lang3-3.4.jar:/opt/hadoop/share/hadoop/common/lib/asm-3.2.jar:/opt/hadoop/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/hadoop/share/hadoop/common/lib/avro-1.7.7.jar:/opt/hadoop/share/hadoop/common/lib/httpclient-4.5.2.jar:/opt/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/hadoop/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/hadoop/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/hadoop/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/hadoop/share/hadoop/common/lib/snappy-java-1.0.5.jar:/opt/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/hadoop/share/hadoop/common/hadoop-common-2.9.0.jar:/opt/hadoop/share/hadoop/common/hadoop-nfs-2.9.0.jar:/opt/hadoop/share/hadoop/common/hadoop-common-2.9.0-tests.jar:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/okhttp-2.4.0.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/hadoop/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/hadoop/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/hadoop/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/hadoop/share/hadoop/hdfs/lib/jackson-core-2.7.8.jar:/opt/hadoop/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/hadoop/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/hadoop/share/hadoop/hdfs/lib/jackson-annotations-2.7.8.jar:/opt/hadoop/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/hadoop/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/hadoop/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/hadoop/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/hadoop/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/hadoop/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/hadoop/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/hadoop/share/hadoop/hdfs/lib/jackson-databind-2.7.8.jar:/opt/hadoop/share/hadoop/hdfs/lib/okio-1.4.0.jar:/opt/hadoop/share/hadoop/hdfs/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/share/hadoop/hdfs/lib/hadoop-hdfs-client-2.9.0.jar:/opt/hadoop/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/hadoop/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/hadoop/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/hadoop/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/hadoop/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-2.9.0-tests.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.9.0.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-nfs-2.9.0.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-2.9.0-tests.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-client-2.9.0.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.9.0-tests.jar:/opt/hadoop/share/hadoop/hdfs/hadoop-hdfs-native-client-2.9.0.jar:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop/share/hadoop/yarn/lib/javassist-3.18.1-GA.jar:/opt/hadoop/share/hadoop/yarn/lib/java-xmlbuilder-0.4.jar:/opt/hadoop/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-configuration-1.6.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-net-3.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/hadoop/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/hadoop/share/hadoop/yarn/lib/gson-2.2.4.jar:/opt/hadoop/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/hadoop/share/hadoop/yarn/lib/woodstox-core-5.0.3.jar:/opt/hadoop/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-digester-1.8.jar:/opt/hadoop/share/hadoop/yarn/lib/HikariCP-java7-2.4.12.jar:/opt/hadoop/share/hadoop/yarn/lib/stax2-api-3.1.4.jar:/opt/hadoop/share/hadoop/yarn/lib/xz-1.0.jar:/opt/hadoop/share/hadoop/yarn/lib/curator-test-2.7.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/share/hadoop/yarn/lib/geronimo-jcache_1.0_spec-1.0-alpha-1.jar:/opt/hadoop/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/hadoop/share/hadoop/yarn/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/hadoop/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/hadoop/share/hadoop/yarn/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/hadoop/share/hadoop/yarn/lib/curator-recipes-2.7.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/hadoop/share/hadoop/yarn/lib/curator-framework-2.7.1.jar:/opt/hadoop/share/hadoop/yarn/lib/api-util-1.0.0-M20.jar:/opt/hadoop/share/hadoop/yarn/lib/json-smart-1.1.1.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-math-2.2.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/hadoop/share/hadoop/yarn/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/hadoop/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/hadoop/share/hadoop/yarn/lib/ehcache-3.3.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jets3t-0.9.0.jar:/opt/hadoop/share/hadoop/yarn/lib/xmlenc-0.52.jar:/opt/hadoop/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/hadoop/share/hadoop/yarn/lib/paranamer-2.3.jar:/opt/hadoop/share/hadoop/yarn/lib/java-util-1.9.0.jar:/opt/hadoop/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/hadoop/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/hadoop/share/hadoop/yarn/lib/jcip-annotations-1.0.jar:/opt/hadoop/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/hadoop/share/hadoop/yarn/lib/activation-1.1.jar:/opt/hadoop/share/hadoop/yarn/lib/json-io-2.5.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jsch-0.1.54.jar:/opt/hadoop/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-beanutils-core-1.8.0.jar:/opt/hadoop/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar:/opt/hadoop/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/hadoop/share/hadoop/yarn/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/share/hadoop/yarn/lib/guice-3.0.jar:/opt/hadoop/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-math3-3.1.1.jar:/opt/hadoop/share/hadoop/yarn/lib/metrics-core-3.0.1.jar:/opt/hadoop/share/hadoop/yarn/lib/httpcore-4.4.4.jar:/opt/hadoop/share/hadoop/yarn/lib/fst-2.50.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-lang3-3.4.jar:/opt/hadoop/share/hadoop/yarn/lib/asm-3.2.jar:/opt/hadoop/share/hadoop/yarn/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/hadoop/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/share/hadoop/yarn/lib/commons-beanutils-1.7.0.jar:/opt/hadoop/share/hadoop/yarn/lib/avro-1.7.7.jar:/opt/hadoop/share/hadoop/yarn/lib/httpclient-4.5.2.jar:/opt/hadoop/share/hadoop/yarn/lib/jsp-api-2.1.jar:/opt/hadoop/share/hadoop/yarn/lib/curator-client-2.7.1.jar:/opt/hadoop/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/hadoop/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/hadoop/share/hadoop/yarn/lib/snappy-java-1.0.5.jar:/opt/hadoop/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/hadoop/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-tests-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-api-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-registry-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-common-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-router-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-common-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-client-2.9.0.jar:/opt/hadoop/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/hadoop/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/hadoop/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/hadoop/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/hadoop/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/hadoop/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/hadoop/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/hadoop/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/hadoop/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/hadoop/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/hadoop/share/hadoop/mapreduce/lib/hadoop-annotations-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/hadoop/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/hadoop/share/hadoop/mapreduce/lib/avro-1.7.7.jar:/opt/hadoop/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/hadoop/share/hadoop/mapreduce/lib/snappy-java-1.0.5.jar:/opt/hadoop/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.9.0-tests.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar:/opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.9.0.jar:/opt/hadoop/contrib/capacity-scheduler/*.jar:/opt/hadoop/contrib/capacity-scheduler/*.jar STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50; compiled by 'arsuresh' on 2017-11-13T23:15Z STARTUP_MSG: java = 1.8.0_162 ************************************************************/ 18/02/20 12:32:57 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 18/02/20 12:32:57 INFO namenode.NameNode: createNameNode [-format] 18/02/20 12:32:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/02/20 12:32:59 WARN common.Util: Path /opt/hadoop/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration. 18/02/20 12:32:59 WARN common.Util: Path /opt/hadoop/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration. Formatting using clusterid: CID-12c8fbd0-1eaf-4d13-8e7b-8d8e37ceb252 18/02/20 12:32:59 INFO namenode.FSEditLog: Edit logging is async:true 18/02/20 12:32:59 INFO namenode.FSNamesystem: KeyProvider: null 18/02/20 12:32:59 INFO namenode.FSNamesystem: fsLock is fair: true 18/02/20 12:32:59 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 18/02/20 12:32:59 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE) 18/02/20 12:32:59 INFO namenode.FSNamesystem: supergroup = supergroup 18/02/20 12:32:59 INFO namenode.FSNamesystem: isPermissionEnabled = true 18/02/20 12:32:59 INFO namenode.FSNamesystem: HA Enabled: false 18/02/20 12:32:59 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 18/02/20 12:32:59 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 18/02/20 12:32:59 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 18/02/20 12:32:59 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 18/02/20 12:32:59 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Feb 20 12:32:59 18/02/20 12:32:59 INFO util.GSet: Computing capacity for map BlocksMap 18/02/20 12:32:59 INFO util.GSet: VM type = 64-bit 18/02/20 12:32:59 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB 18/02/20 12:32:59 INFO util.GSet: capacity = 2^21 = 2097152 entries 18/02/20 12:33:00 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 18/02/20 12:33:00 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 18/02/20 12:33:00 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 18/02/20 12:33:00 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 18/02/20 12:33:00 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 18/02/20 12:33:00 INFO blockmanagement.BlockManager: defaultReplication = 1 18/02/20 12:33:00 INFO blockmanagement.BlockManager: maxReplication = 512 18/02/20 12:33:00 INFO blockmanagement.BlockManager: minReplication = 1 18/02/20 12:33:00 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 18/02/20 12:33:00 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 18/02/20 12:33:00 INFO blockmanagement.BlockManager: encryptDataTransfer = false 18/02/20 12:33:00 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 18/02/20 12:33:00 INFO namenode.FSNamesystem: Append Enabled: true 18/02/20 12:33:00 INFO util.GSet: Computing capacity for map INodeMap 18/02/20 12:33:00 INFO util.GSet: VM type = 64-bit 18/02/20 12:33:00 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB 18/02/20 12:33:00 INFO util.GSet: capacity = 2^20 = 1048576 entries 18/02/20 12:33:01 INFO namenode.FSDirectory: ACLs enabled? false 18/02/20 12:33:01 INFO namenode.FSDirectory: XAttrs enabled? true 18/02/20 12:33:01 INFO namenode.NameNode: Caching file names occurring more than 10 times 18/02/20 12:33:01 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false 18/02/20 12:33:01 INFO util.GSet: Computing capacity for map cachedBlocks 18/02/20 12:33:01 INFO util.GSet: VM type = 64-bit 18/02/20 12:33:01 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB 18/02/20 12:33:01 INFO util.GSet: capacity = 2^18 = 262144 entries 18/02/20 12:33:01 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 18/02/20 12:33:01 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 18/02/20 12:33:01 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 18/02/20 12:33:01 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 18/02/20 12:33:01 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 18/02/20 12:33:01 INFO util.GSet: Computing capacity for map NameNodeRetryCache 18/02/20 12:33:01 INFO util.GSet: VM type = 64-bit 18/02/20 12:33:01 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB 18/02/20 12:33:01 INFO util.GSet: capacity = 2^15 = 32768 entries 18/02/20 12:33:01 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1005057487-10.0.1.50-1519129981121 18/02/20 12:33:01 INFO common.Storage: Storage directory /opt/hadoop/dfs/name has been successfully formatted. 18/02/20 12:33:01 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 18/02/20 12:33:01 INFO namenode.FSImageFormatProtobuf: Image file /opt/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds. 18/02/20 12:33:01 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 18/02/20 12:33:01 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lxchadoopmaster/10.0.1.50 ************************************************************/
Configurações especificas dos Slave Nodes:
# vi hdfs-site.xml # Adicionar dentro da tag configuration <property> <name>dfs.data.dir</name> <value>/opt/hadoop/dfs/name/data</value> <final>true</final> </property>
Criar a diretoria onde o dfs irá armazenar dados e atribuir as permissões corretas:
# mkdir /opt/hadoop/dfs/name/data -p # chown hadoop.hadoop /opt/hadoop/dfs/name/data
Finalmente efetuar boot ao Hadoop.
# su - hadoop $ start-dfs.sh
[hadoop@lxcHadoopMaster ~]$ start-dfs.sh 18/02/20 13:24:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [lxchadoopmaster] lxchadoopmaster: starting namenode, logging to /opt/hadoop/logs/hadoop-hadoop-namenode-lxcHadoopMaster.out lxchadoopslave01: starting datanode, logging to /opt/hadoop/logs/hadoop-hadoop-datanode-lxchadoopslave01.out lxchadoopslave02: starting datanode, logging to /opt/hadoop/logs/hadoop-hadoop-datanode-lxchadoopslave02.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/logs/hadoop-hadoop-secondarynamenode-lxcHadoopMaster.out
Vamos testar agora a nossa solução:
$ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/hadoop $ hdfs dfs -put /opt/hadoop/hadoop-2.9.0.tar.gz /user/hadoop
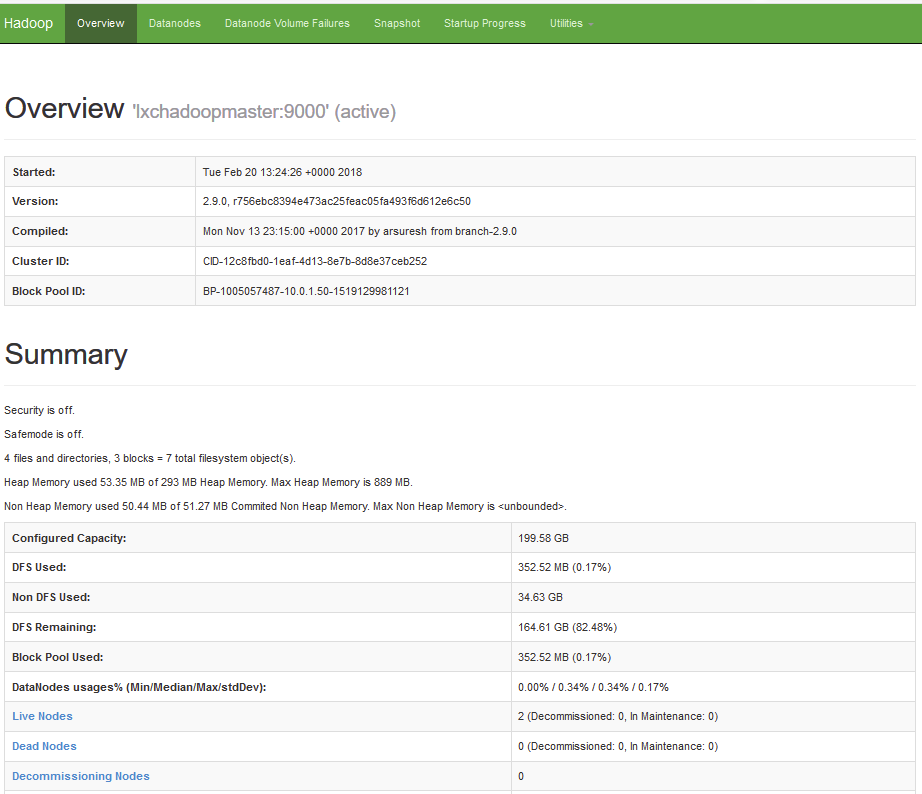
# su - hadoop $ hdfs dfsadmin -report Configured Capacity: 214299746304 (199.58 GB) Present Capacity: 177115291648 (164.95 GB) DFS Remaining: 176745652224 (164.61 GB) DFS Used: 369639424 (352.52 MB) DFS Used%: 0.21% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (2): Name: 10.0.1.51:50010 (lxchadoopslave01) Hostname: lxchadoopslave01 Decommission Status : Normal Configured Capacity: 107149873152 (99.79 GB) DFS Used: 369631232 (352.51 MB) Non DFS Used: 18407415808 (17.14 GB) DFS Remaining: 88372826112 (82.30 GB) DFS Used%: 0.34% DFS Remaining%: 82.48% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 20 13:43:24 UTC 2018 Last Block Report: Tue Feb 20 13:24:39 UTC 2018 Name: 10.0.1.52:50010 (lxchadoopslave02) Hostname: lxchadoopslave02 Decommission Status : Normal Configured Capacity: 107149873152 (99.79 GB) DFS Used: 8192 (8 KB) Non DFS Used: 18777038848 (17.49 GB) DFS Remaining: 88372826112 (82.30 GB) DFS Used%: 0.00% DFS Remaining%: 82.48% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 20 13:43:24 UTC 2018 Last Block Report: Tue Feb 20 13:24:39 UTC 2018
Graficamente também é possível visualizar a nossa solução, bastando apontar o nosso browser para o ip do master node, porta 50070:
http://<hadoopnode>:50070/explorer.html#/user/hadoop/

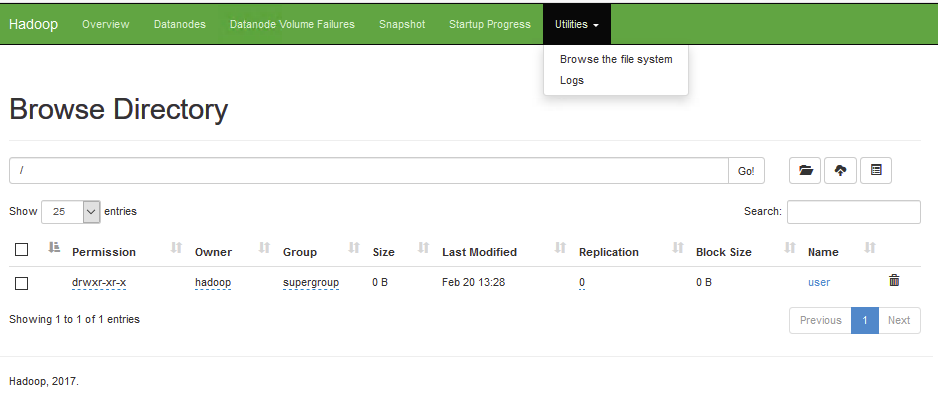
Temos agora o layer de storage que é o HDFS, e que poderá ser integrado com mais componentes de forma a garantir armazenamento, consulta e batch processing conforme o desejado.

Em termos de recursos, e tendo em conta que o load neste momento é mínimo, o comportamento dos containers que contem os ambientes de master e slave, tem o seguinte consumo de recursos ao nível do virtualizador:
# lxc-info --name lxcHadoopMaster Name: lxcHadoopMaster State: RUNNING PID: 16796 IP: 10.0.1.50 CPU use: 7.74 seconds BlkIO use: 71.84 MiB Memory use: 245.66 MiB KMem use: 0 bytes Link: vethYT8FS6 TX bytes: 745.84 MiB RX bytes: 528.80 MiB Total bytes: 1.24 GiB
# lxc-info --name lxcHadoopSlave01 Name: lxcHadoopSlave01 State: RUNNING PID: 10177 IP: 10.0.1.51 CPU use: 0.81 seconds BlkIO use: 36.86 MiB Memory use: 255.78 MiB KMem use: 0 bytes Link: vethD16G04 TX bytes: 11.53 MiB RX bytes: 1.07 GiB* Total bytes: 1.08 GiB
# lxc-info --name lxcHadoopSlave02 Name: lxcHadoopSlave02 State: RUNNING PID: 10386 IP: 10.0.1.52 CPU use: 0.54 seconds BlkIO use: 36.53 MiB Memory use: 244.32 MiB KMem use: 0 bytes Link: veth6GBUAV TX bytes: 8.74 MiB* RX bytes: 370.46 MiB Total bytes: 379.21 MiB
Chegamos ao fim de mais um post, desta vez, do layer de storage para Big Data!
Irei em breve fazer um post, onde será integrado o Elastic com o hdfs para fornecer analise analítica dos dados armazenados no nosso Lab de Hadoop.
Caso tenham alguma duvida sabem onde me podem encontrar, ou em alternativa, enviem-me um email para nuno[at]nuneshiggs.com
Até já!
Nuno
Referencias: http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html