Bom dia a todos,
Tenho feito alguns posts de elasticsearch, e tenho me esquecido de referir uma excelente ferramenta para uso em selfhosted datacenter, cloud e homelab: O Splunk.
Presença fundamental no meu homelab desde que me lembro, e em grande numero dos meus Clientes, com muito menos peso em recursos de sistema quando comparado com o elasticsearch, e um ecossistema interno aplicacional excelente o splunk é uma força formidável no mundo dos SIEM’s, AIOps, Application Management e Log Management.
O que é o Splunk?
É um plataforma que captura logs, os indexa, e faz correlação em tempo real, de dados, num repositório indexável que nos pode gerar gráficos, relatórios, alertas, dashboards e visualizações de dados.
Em termos tecnológicos é uma tecnologia horizontal, que é utilizada em gestão aplicacional, compliance e segurança, assim bem como em analise analítica para logs de servidor, componentes web e componentes aplicacionais, nunca esquecendo a componente de negócio.
É um concorrente direto do elasticsearch e dos variantes da stack ELK.
![]()
O splunk é um produto com componente free, que é idêntico em tudo ao seu irmão maior e enterprise ready, apenas a limitação do numero de eventos em termos de MB’s (500MB de logs/dia) que podem ser indexados por dia.
Tirando isso, é totalmente funcional.
Como instalar o splunk:
Após criar uma conta no site da empresa que produz o produto, é prosseguir para a parte de downloads e escolher a parte free:
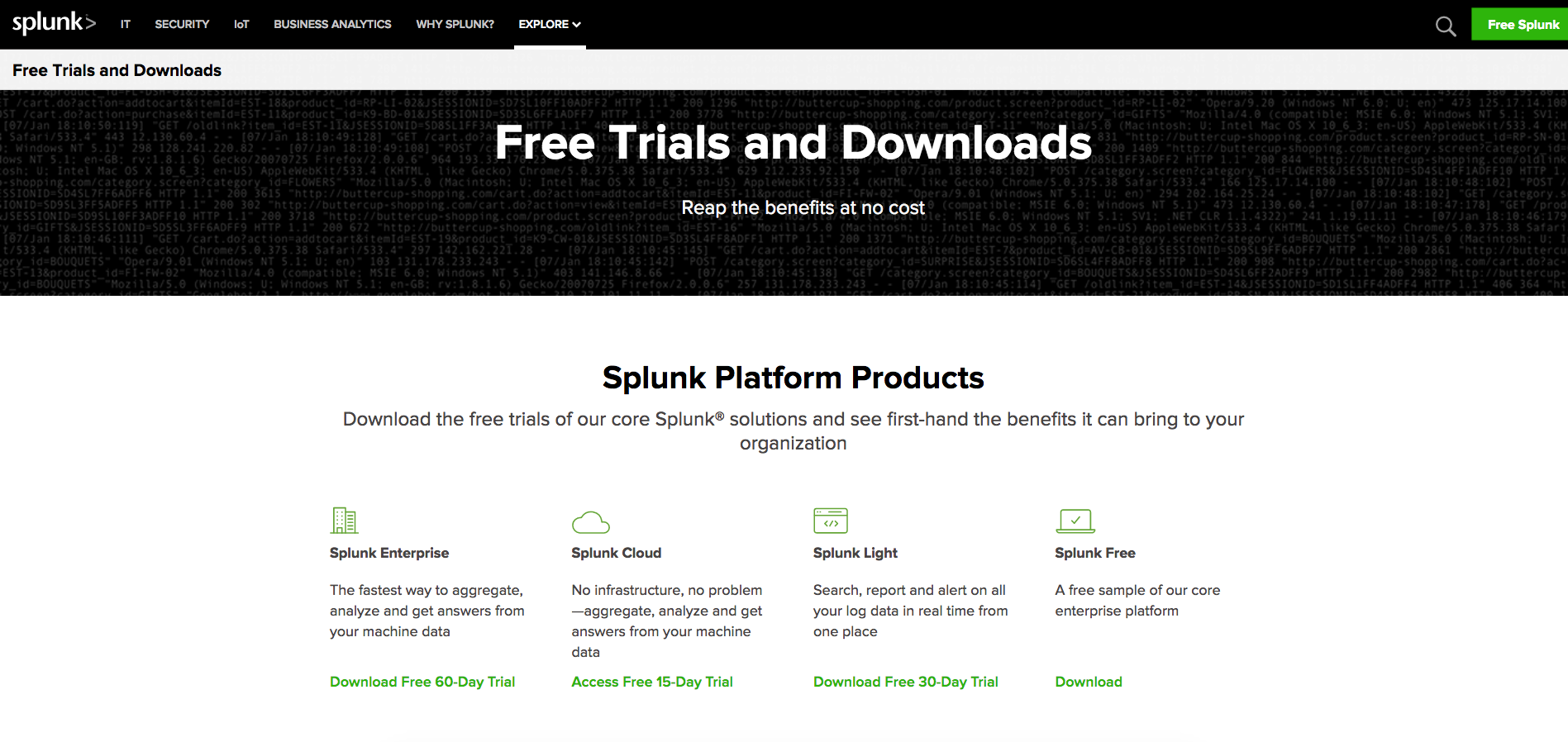
Escolher a versão que melhor se adapta a nossa realidade:

Os requisitos para instalação podem ser encontrados aqui, mas em termos de mundo real, os valores são bem mais modestos do que os recomendados em stacks ELK.
A instalação em si, e após a criação da vossa VM/LXC Container é relativamente simples:
# yum localinstall splunk-7.3.1.1-7651b7244cf2-linux-2.6-x86_64.rpm
Finalmente arrancamos o serviço através do comando:
/opt/splunk/bin/splunk start
Respondendo em seguida ao EULA que irá ser mostrado na consola de SSH.
O acesso em seguida poderá ser feito através de wegbui, no endereço http://IP:8500

No primeiro login ser-vos-a pedida a password de admin com a qual podem configurar o sistema.
Em seguida e como para indexar dados, necessitamos alem do indexador de dados, vamos adicionar uma ou mais datasources.
Neste campo o splunk dá igualmente cartas, não necessitando de ingest’s de logs como o logstash, sendo que a componente vem built-in na stack aplicacional inicial.
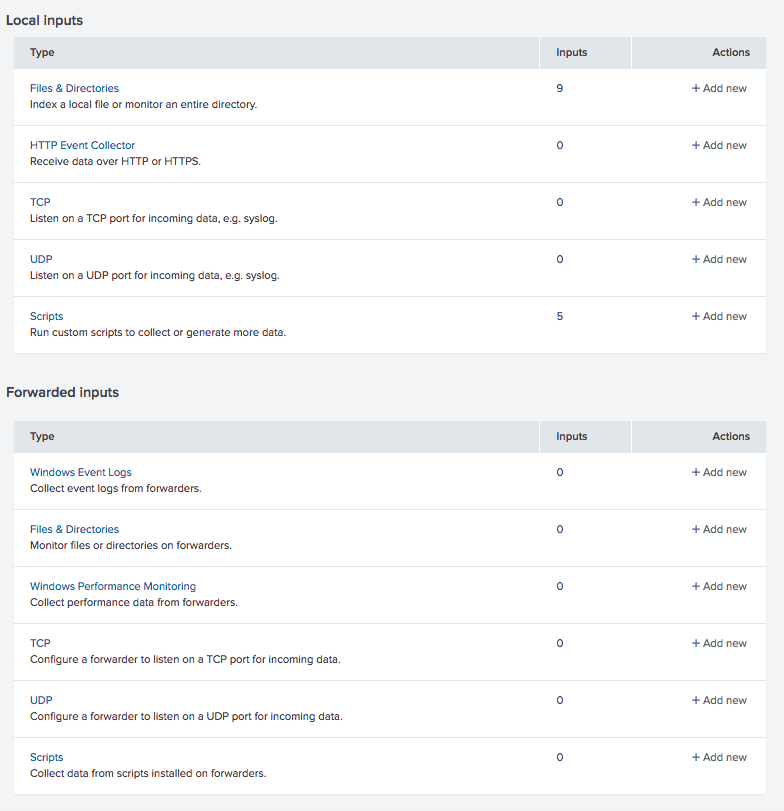
Para tal, vamos a settings, Data Inputs,
 Em seguida escolher a secção Files & Directories:
Em seguida escolher a secção Files & Directories:
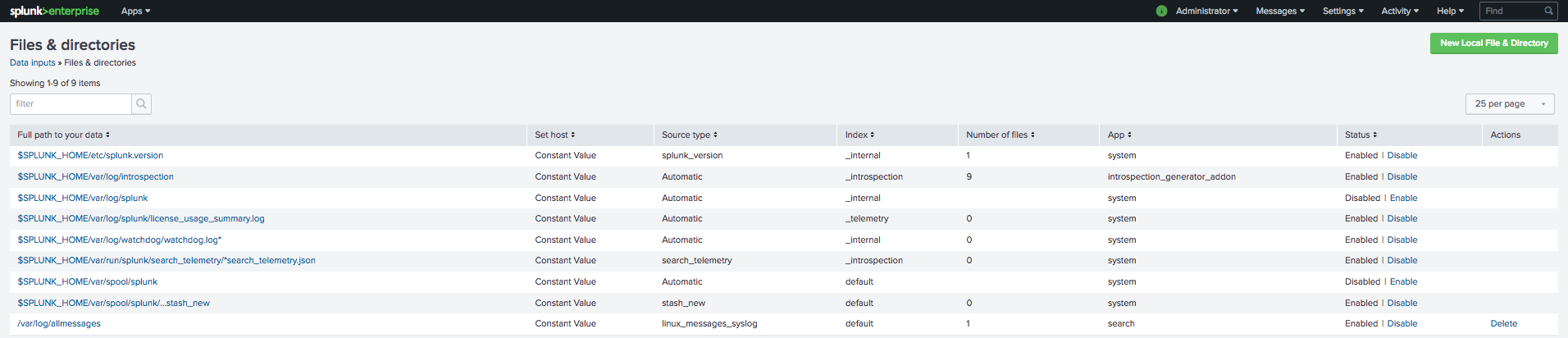
Finalmente, escolhemos New Local File & Directory, e escolhemos o ficheiro de syslog, no meu caso o allmessages a indexar pelo Splunk.
Após uns momentos de indexação, os nossos dados já irão ser visíveis na consola principal:
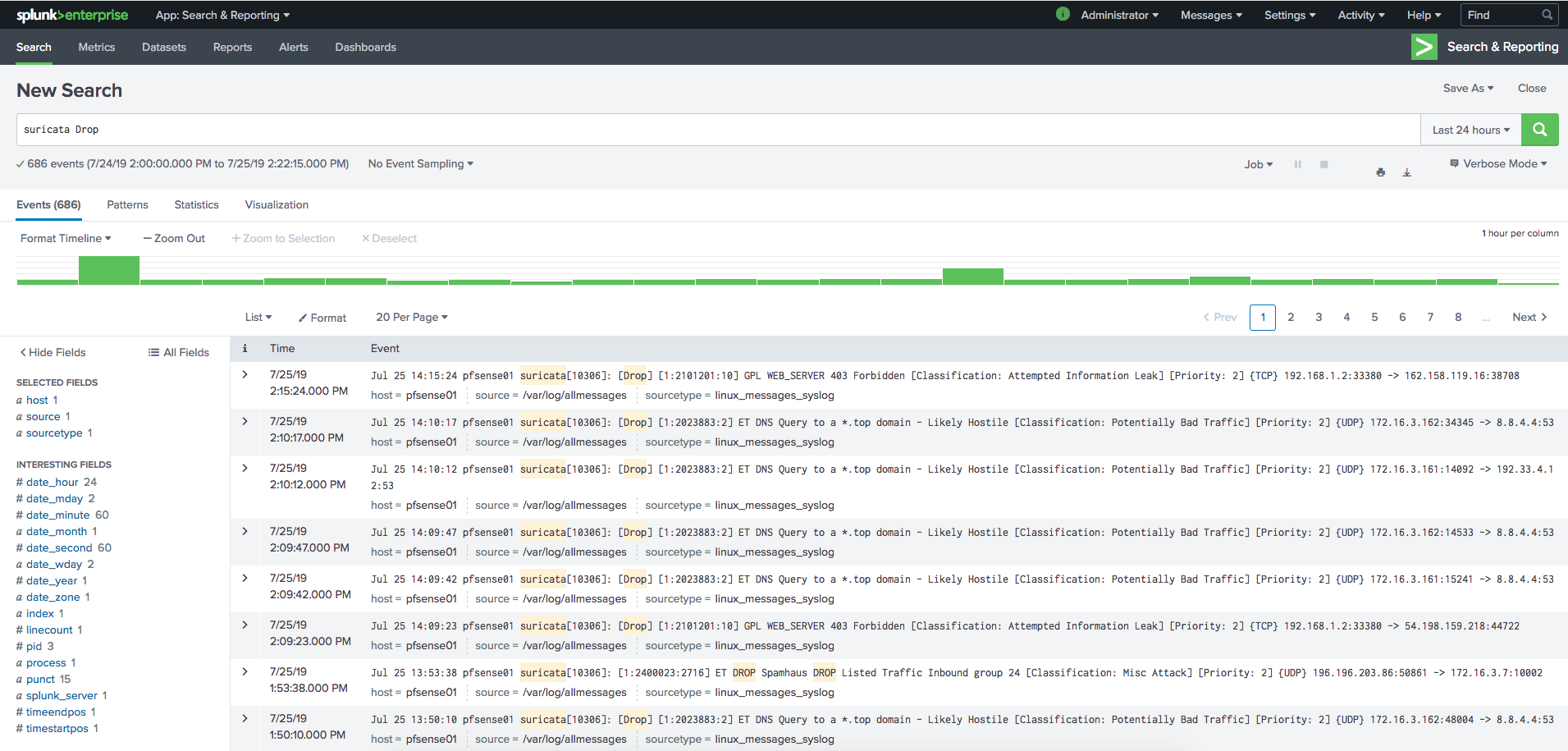
Neste caso procurei por eventos IPS de segurança da minha firewall, através do search terms Suricata e Drop. Se passarem com o rato por cima de uma das palavras, ele irá construir a expressão de query que inclua esse termo.
Todo o drilldown dos dados pode ser feito, dependendo da imaginação de cada um.
Outra feature excelente do splunk é a app store deles:
Após o login, escolher a secção + Find More Apps:
E escolher quais as apps que desejam. E tem muito por onde escolher em múltiplas categorias:
Este foi um bird’s-eye-view estratósférico da capacidade do splunk de indexação e num dos próximos posts que irei apresentar, irei dar algumas dicas para reconfigurarem o vosso syslog, para separar os dados que vem de cada host remoto por ficheiro, como carregar ficheiros não de sistema no syslog, e como configurar o splunk para vos enviar um email especifico quando uma situação que definam ocorra.
Sim, sei que posso entregar diretamente os meus logs ao splunk e não passar pelo layer do syslog, mas gosto de ter os dados em outros formatos para ter material de processamento para fazer posts como estes.
Até ao próximo post! Se tiverem duvidas ou reparos sabem onde me encontrar.
Um abraço!
Nuno