Olá a todos,
No seguimento do nosso ultimo post da semana passada, sobre motores de inferência públicos de AI, hoje venho mostrar como fazer uso deles no nosso ambiente on-prem.
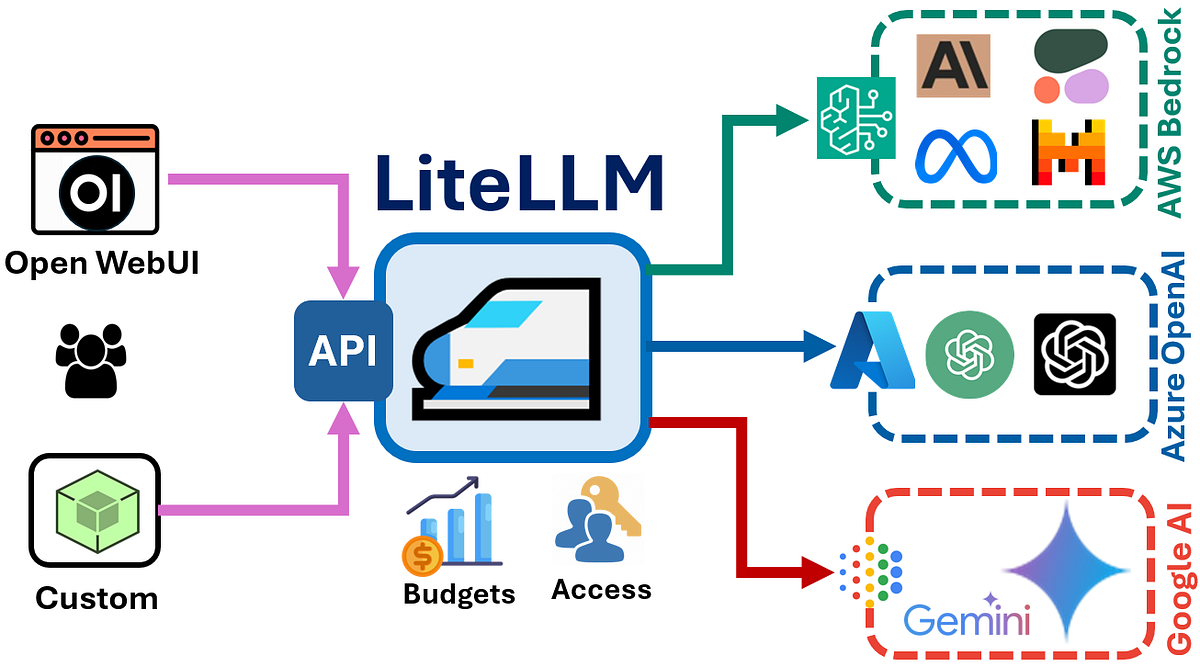
O LiteLLM surge como uma solução elegante para este desafio, oferecendo uma interface unificada para diversos fornecedores de IA, incluindo as opções gratuitas que exploramos anteriormente neste post.
Neste artigo, vamos mergulhar na implementação prática do LiteLLM utilizando Docker, criando um ambiente robusto e escalável para o seu motor de inferência. Esta abordagem não só simplifica o processo de deployment como também garante consistência entre diferentes ambientes de desenvolvimento e produção.
O Que é o LiteLLM?
O LiteLLM é uma biblioteca Python / Service que funciona como um proxy unificado para múltiplos fornecedores de LLM. Sua principal vantagem reside na capacidade de abstrair as diferenças entre APIs de diferentes fornecedores, oferecendo uma interface consistente baseada no formato OpenAI. Isto significa que pode alternar entre fornecedores como Groq, Together AI, Replicate, ou mesmo os nossos modelos locais, mantendo o mesmo código cliente.
Esta flexibilidade torna-se particularmente valiosa quando trabalhamos com fornecedores gratuitos, onde limitações de rate limiting ou disponibilidade podem exigir mudanças rápidas entre diferentes serviços, ou queremos balancear carga de carga para os nosso homelab nunca ficar sem recursos.
Arquitetura da Solução
A implementação de hoje seguirá uma arquitetura baseada em containers, onde o LiteLLM funcionará como um proxy server que:
- Recebe requests HTTP no formato OpenAI API
- Encaminha para o fornecedor apropriado
- Normaliza as respostas
- Implementa features como rate limiting, caching e load balancing
Esta abordagem oferece várias vantagens práticas:
- Isolamento: Cada instância-componente do LiteLLM roda em seu próprio container
- Escalabilidade: Fácil adição de novas instâncias conforme necessário
- Manutenibilidade: Updates e rollbacks simplificados
- Portabilidade: Funciona consistentemente em qualquer ambiente que suporte Docker
Implementação com Docker
Comecemos criando um Dockerfile otimizado para nossa aplicação:
FROM python:3.11-slim
# Definir variáveis de ambiente
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1 # Criar utilizador não-root para segurança
RUN groupadd -g 1000 litellm && \
useradd -r -u 1000 -g litellm litellm
# Instalar dependências do sistema
RUN apt-get update && \
apt-get install -y --no-install-recommends \
curl \
&& rm -rf /var/lib/apt/lists/*
# Definir diretório de trabalho
WORKDIR /app
# Copiar requirements e instalar dependências Python
COPY requirements.txt .
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
# Copiar código da aplicação
COPY config/ ./config/
COPY scripts/ ./scripts/
# Definir permissões
RUN chown -R litellm:litellm /app
# Mudar para user não-root
USER litellm
# Expor porta
EXPOSE 4000
# Health check
HEALTHCHECK --interval=30s --timeout=10s --start-period=5s --retries=3 \
CMD curl -f http://localhost:4000/health || exit 1
# Comando padrão
CMD ["litellm", "--config", "config/litellm_config.yaml", "--port", "4000", "--host", "0.0.0.0"]
Docker Compose para Orquestração
Para facilitar a gestão do produto, utilizaremos Docker Compose:
version: '3.8'
services:
litellm-proxy:
build:
context: .
dockerfile: Dockerfile
container_name: litellm-proxy
ports:
- "4000:4000"
environment:
- GROQ_API_KEY=${GROQ_API_KEY}
- TOGETHER_API_KEY=${TOGETHER_API_KEY}
- REPLICATE_API_TOKEN=${REPLICATE_API_TOKEN}
- HUGGINGFACE_API_KEY=${HUGGINGFACE_API_KEY}
volumes:
- ./config:/app/config:ro
- ./logs:/app/logs
restart: unless-stopped
networks:
- litellm-network
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:4000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
redis-cache:
image: redis:7-alpine
container_name: litellm-redis
command: redis-server --appendonly yes
volumes:
- redis-data:/data
networks:
- litellm-network
restart: unless-stopped
prometheus:
image: prom/prometheus:latest
container_name: litellm-prometheus
ports:
- "9090:9090"
volumes:
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- prometheus-data:/prometheus
networks:
- litellm-network
restart: unless-stopped
volumes:
redis-data:
prometheus-data:
networks:
litellm-network:
driver: bridge
Configuração Avançada do LiteLLM
Arquivo de Configuração YAML Completo
Aqui está um exemplo abrangente de configuração que demonstra as capacidades avançadas do LiteLLM:
# litellm_config.yaml
model_list:
# Configurações Groq (Gratuito)
- model_name: llama-3.1-70b
litellm_params:
model: groq/llama-3.1-70b-versatile
api_key: os.environ/GROQ_API_KEY
max_tokens: 8000
temperature: 0.7
model_info:
mode: chat
supports_function_calling: true
supports_vision: false
- model_name: mixtral-8x7b
litellm_params:
model: groq/mixtral-8x7b-32768
api_key: os.environ/GROQ_API_KEY
max_tokens: 32000
temperature: 0.5
# Configurações Together AI (Gratuito com limitações)
- model_name: llama-3.1-8b-together
litellm_params:
model: together_ai/meta-llama/Llama-3.1-8B-Instruct-Turbo
api_key: os.environ/TOGETHER_API_KEY
max_tokens: 4000
model_info:
mode: chat
cost_per_token: 0.0
- model_name: qwen-72b-together
litellm_params:
model: together_ai/Qwen/Qwen2.5-72B-Instruct-Turbo
api_key: os.environ/TOGETHER_API_KEY
max_tokens: 8000
# Configurações Replicate
- model_name: llama-3.1-405b-replicate
litellm_params:
model: replicate/meta/meta-llama-3.1-405b-instruct
api_key: os.environ/REPLICATE_API_TOKEN
max_tokens: 4000
model_info:
mode: chat
cost_per_token: 0.0015
# Configurações Hugging Face (Modelos gratuitos)
- model_name: zephyr-7b-hf
litellm_params:
model: huggingface/HuggingFaceH4/zephyr-7b-beta
api_key: os.environ/HUGGINGFACE_API_KEY
max_tokens: 2000
model_info:
mode: chat
cost_per_token: 0.0
# Configurações do Router para Load Balancing
router_settings:
routing_strategy: least-busy
fallbacks:
- llama-3.1-70b: [mixtral-8x7b, llama-3.1-8b-together]
- qwen-72b-together: [llama-3.1-70b, mixtral-8x7b]
# Rate Limiting por modelo
rpm_limit: 100
tpm_limit: 40000
# Retry logic
num_retries: 3
retry_delay: 1.0
timeout: 30.0
# Configurações de Cache
cache:
type: redis
host: litellm-redis
port: 6379
ttl: 600 # 10 minutos
# Configuração de cache semântico
semantic_similarity_threshold: 0.95
# Configurações de Logging
litellm_settings:
success_callback: ["prometheus", "langfuse"]
failure_callback: ["prometheus", "langfuse"]
# Callbacks personalizados
callbacks:
- custom_logger
- cost_tracker
- performance_monitor
# Configurações de Segurança
general_settings:
master_key: os.environ/LITELLM_MASTER_KEY
database_url: os.environ/DATABASE_URL
# Configurações de autenticação
ui_username: admin
ui_password: os.environ/LITELLM_UI_PASSWORD
# CORS
allow_cors: true
cors_origins: ["http://localhost:3000", "https://seu-frontend.com"]
# Configurações de Rate Limiting Global
global_rate_limit:
rpm: 1000
tpm: 100000
max_parallel_requests: 50
# Configurações de Health Check
health_check:
enabled: true
interval: 30
timeout: 10
# Configurações de Alerting
alerting:
slack_webhook: os.environ/SLACK_WEBHOOK_URL
email_alerts: true
alert_types:
- high_error_rate
- rate_limit_exceeded
- model_unavailable
- high_latency
# Configurações de Métricas
metrics:
prometheus:
enabled: true
port: 4001
custom_metrics:
- request_duration
- tokens_processed
- cost_tracking
- model_performance
# Configurações Específicas por Fornecedor
provider_settings:
groq:
max_parallel_requests: 10
request_timeout: 30
together_ai:
max_parallel_requests: 5
request_timeout: 45
replicate:
max_parallel_requests: 3
request_timeout: 120
webhook_url: https://seu-dominio.com/webhook
huggingface:
max_parallel_requests: 8
request_timeout: 60
# Configurações de Deployment
deployment:
environment: production
version: "1.0.0"
region: eu-west-1
# Auto-scaling
auto_scale:
enabled: true
min_instances: 2
max_instances: 10
target_cpu_utilization: 70
# Configurações de Backup e Recovery
backup:
enabled: true
interval: "0 2 * * *" # Diário às 2h
retention_days: 30
storage_backend: s3
# Configurações de Desenvolvimento
development:
debug_mode: false
verbose_logging: true
mock_responses: false
# Testing
test_models: ["llama-3.1-8b-together"]
load_test_config:
concurrent_users: 100
ramp_up_time: 300
test_duration: 600
Scripts de Automação
Shutout to all my lake district runabout friends 🙂
Script de Inicialização
Para garantir um arranque consistente em todos os arranques criemos um script para facilitar o setup inicial:
#!/bin/bash
# scripts/setup.sh
set -e
echo "A configurar ambiente LiteLLM..."
# Criar diretórios necessários
mkdir -p config logs monitoring
# Verificar variáveis de ambiente obrigatórias
required_vars=("GROQ_API_KEY" "TOGETHER_API_KEY" "LITELLM_MASTER_KEY")
for var in "${required_vars[@]}"; do
if [[ -z "${!var}" ]]; then
echo "Variável de ambiente $var não definida"
exit 1
fi
done
# Criar arquivo .env se não existir
if [[ ! -f .env ]]; then
echo "A criar arquivo .env template..."
cat > .env << EOF
# API Keys para fornecedores gratuitos
GROQ_API_KEY=your_groq_api_key_here
TOGETHER_API_KEY=your_together_api_key_here
REPLICATE_API_TOKEN=your_replicate_token_here
HUGGINGFACE_API_KEY=your_hf_api_key_here
# Configurações LiteLLM
LITELLM_MASTER_KEY=$(openssl rand -hex 32)
LITELLM_UI_PASSWORD=$(openssl rand -base64 12)
# Configurações opcionais
SLACK_WEBHOOK_URL=
DATABASE_URL=postgresql://user:pass@localhost/litellm
EOF
echo "Arquivo .env criado. Configure suas API keys!"
fi
# Build da imagem Docker
echo "Construindo imagem Docker..."
docker-compose build
# Verificar configuração
echo "Validando configuração..."
docker-compose config
echo "Setup concluído! Execute 'docker-compose up -d' para iniciar."
Script de Health Check
Em seguida teremos de criar um script que valide a sanidade dos componentes em execução:
#!/bin/bash
# scripts/health_check.sh
LITELLM_URL=${1:-"http://localhost:4000"}
echo "A verificar a saúde do LiteLLM..."
# Health check básico
if curl -s -f "$LITELLM_URL/health" > /dev/null; then
echo "Serviço respondendo"
else
echo "Serviço não responde"
exit 1
fi
# Testar modelos disponíveis
echo "Modelos disponíveis:"
curl -s "$LITELLM_URL/v1/models" | jq -r '.data[].id'
# Teste de inferência simples
echo "A testar a inferência..."
response=$(curl -s -X POST "$LITELLM_URL/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.1-70b",
"messages": [{"role": "user", "content": "Hello, world!"}],
"max_tokens": 50
}')
if echo "$response" | jq -e '.choices[0].message.content' > /dev/null; then
echo "Inferência funcionando"
echo "Resposta: $(echo "$response" | jq -r '.choices[0].message.content')"
else
echo "Falha na inferência"
echo "$response"
exit 1
fi
echo "Todos os testes passaram!"
Monitoramento e Observabilidade
Configuração do Prometheus:
Finalmente e para termos métricas e visibilidade do que se está a passar na nossa solução:
# monitoring/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'litellm'
static_configs:
- targets: ['litellm-proxy:4001']
scrape_interval: 10s
metrics_path: /metrics
- job_name: 'redis'
static_configs:
- targets: ['litellm-redis:6379']
Integração com Aplicações Cliente
Finalmente e para demonstrar a utilização utilizando python (pedi ao meu LLM para o fazer).
import openai
# Configurar cliente para usar nosso proxy LiteLLM
client = openai.OpenAI(
base_url="http://localhost:4000/v1",
api_key="o-vosso-master-key-aqui"
)
# Usar como qualquer cliente OpenAI
response = client.chat.completions.create(
model="llama-3.1-70b",
messages=[
{"role": "system", "content": "Tu és um assistente útil."},
{"role": "user", "content": "Explique machine learning em termos simples."}
],
max_tokens=500,
temperature=0.7
)
print(response.choices[0].message.content)
Melhores Práticas e Otimizações
Gestão de Recursos
Como em tudo na vida, o truque está na optimização do que se faz. Seja em capacidade para a nossa chave não ser banida de nenhum engine, seja em termos de segurança, especialmente se quiserem expor isto através de reverse-proxy para usarem por exemplo via vscode quando estão fora do vosso homelab.
- Rate Limiting: Configure limites apropriados para evitar exceder quotas gratuitas
- Caching Inteligente: Use cache semântico para reduzir chamadas desnecessárias
- Fallback Strategy: Implemente fallbacks robustos entre fornecedores
- Monitoring Proativo: Configure alertas para indisponibilidade de serviços
Segurança
- Variáveis de Ambiente: Nunca usem API keys hardcoded.
- Utilizador Não-Root: Execute containers com utilizador limitados
- Network Isolation: Use redes Docker isoladas
- HTTPS: Sempre use TLS em produção
- Reverse Proxy: Sempre que expuserem o liteLLM á internet façam por detrás de um reverse-proxy, preferencialmente com uma WAF (como o modsecurity com OWASP) á frente.
- Keys em separado: Para cada uma das aplicações que existem criem uma key nova. Não partilhem entre aplicações keys. Irão me agradecer depois, sempre que quiserem desautorizar um acesso apenas.
E chegamos ao fim de mais um post semanal. Neste post que hoje foi mais técnico, vimos como a implementação do LiteLLM com Docker oferece uma solução robusta e escalável para integração com múltiplos fornecedores de LLM, especialmente valiosa quando trabalhamos com serviços gratuitos que podem ter limitações variáveis.
Esta arquitetura não só simplifica o desenvolvimento como também proporciona flexibilidade operacional crucial em ambientes de produção.
A configuração apresentada demonstra como criar um sistema que pode alternar seamlessly entre diferentes fornecedores, implementar caching inteligente, monitorização abrangente e recuperação automática de falhas. Estes elementos são fundamentais para construir aplicações resilientes que dependem de serviços externos.
Com esta base sólida, podemos expandir e customizar conforme as nossas necessidades específicas, adicionando novos fornecedores, implementando lógicas de roteamento mais sofisticadas ou integrando com ferramentas de observabilidade mais avançadas. O importante é manter o foco na simplicidade operacional e na confiabilidade do sistema.
Até ao post da próxima semana. Se virem alguma coisa menos correcta já sabem onde me encontrar.
Abraço!
Nuno