Olá a todos!
Hoje vou falar-vos de algo que aprendi em tempos da pior maneira possível: a importância de ter um sistema automático e inteligente de orquestração de shutdown quando a energia falha no vosso homelab. E sim, aprendi isto depois de perder dados e passar uma noite inteira a recuperar sistemas. Spoiler: não foi divertido.
Mas antes de vos contar a minha história (que envolve um UPS com uma avaria silenciosa, VMs a correr sem orquestração, e um corte de energia às 3 da manhã), deixem-me apresentar-vos o Eneru – um daemon de monitorização de UPS que pode literalmente salvar o vosso homelab de um desastre.
A História que ninguém quer viver
Imaginem o cenário: Era uma quinta-feira normal. O meu homelab estava a funcionar lindamente – 17 VMs entre Rocky Linux, openSUSE e Alpine Linux, containers Docker a correr aplicações críticas, NAS montado via NFS com terabytes de dados, reverse proxies, WAFs, stacks de automatização com Ansible e puppet… enfim, o setup completo.
Às 3h17 da manhã (eu sei a hora exata porque os logs não me deixam esquecer a data), houve um corte de energia no bairro. O UPS ativou-se como deveria. Tudo normal até aqui, certo? ERRADO.
O que aconteceu a seguir foi uma cascata de falhas:
- O UPS aguentou cerca de 12 minutos (bateria já com os seus anos)
- As VMs continuaram a correr até ao fim, consumindo bateria
- Os containers não pararam graciosamente
- O NAS, ligado ao mesmo UPS mas sem comunicação com o host principal, desligou-se abruptamente
- As montagens NFS ficaram penduradas (hung mounts)
- Quando a energia voltou, metade das VMs não arrancou corretamente
- Filesystem corruption *serio* em duas VMs
- Cluster Percona inconsistente (felizmente tinha backups válidos e testados)
- Containers com dados inconsistentes
O resultado? Passei o resto da noite e parte da manhã seguinte a recuperar sistemas, a correr fsck, a restaurar backups, e a rezar para que os backups automáticos tivessem funcionado (spoiler do spoiler: alguns não tinham, o que nos leva sempre a maxima do Schrodinger).
O custo total? Cerca de 8 horas de trabalho manual, dois dias de downtime parcial de alguns serviços, e uma lição de vida que não vou esquecer: se têm um homelab a sério ou instalação on-premise, precisam de orquestração de shutdown automática.
Enter Eneru: O daemon que devia ter instalado antes
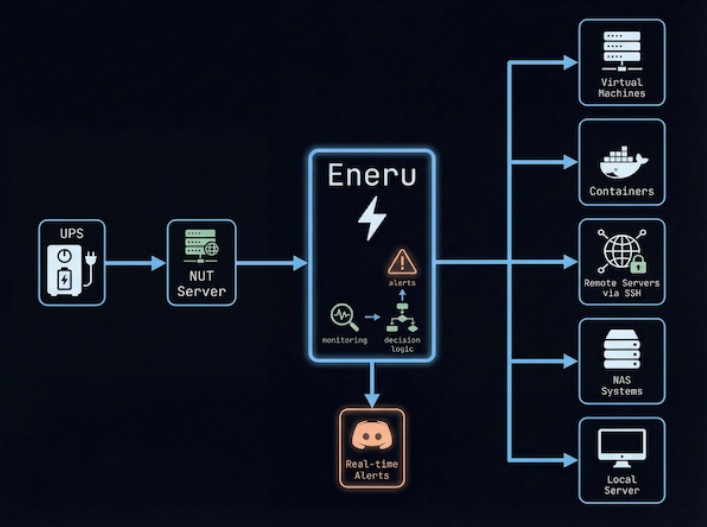
O Eneru é basicamente o que eu implementei manualmente depois daquele desastre, mas feito da forma correcta por alguém que claramente já passou pelo mesmo que eu. É um daemon Python que monitoriza o vosso UPS através do NUT (Network UPS Tools) e orquestra um shutdown gracioso e coordenado de toda a vossa infraestrutura quando as coisas começam a correr mal.
E quando digo “orquestrado”, não estou a falar de um simples shutdown -h now. Estou a falar de uma sequência completa e inteligente:
- Monitorizaação contínua do estado do UPS
- Detecção de múltiplos triggers de shutdown (não só bateria baixa)
- Paragem graciosaa de VMs (libvirt/KVM)
- Stop de containers Docker/Podman
- Sync de filesystems
- Unmount de montagens remotas (com timeout / lazy para evitar hangs)
- Shutdown de servidores remotos via SSH
- Shutdown final do host local
- Notificações em tempo real via Discord/Slack/Telegram/etc
Tudo isto de forma automática, não bloqueante, e com fallbacks para cada etapa.
Os Triggers Inteligentes: Porque “Bateria a 20%” não chega
Uma das coisas que mais me impressionou no Eneru foi o sistema de triggers múltiplos. A maioria das soluções caseiras que vejo por aí fazem algo tipo:
if battery < 20%; then
shutdown now
fi
O problema? Baterias envelhecidas mentem. UPS com estimativas de runtime pouco fiáveis mentem. E quando mentem, ou desligam demasiado cedo (desperdício de autonomia) ou demasiado tarde (perda de dados).
O Eneru usa cinco triggers independentes, cada um a proteger contra cenários diferentes:
- FSD Flag (Forced Shutdown)
Quando o próprio UPS diz “malta, está na altura de desligar AGORA”. Prioridade máxima. - Low Battery Threshold
O clássico. Bateria abaixo de X% (configurável, default 20%). Simples mas eficaz. - Critical Runtime
Não é só o nível de bateria que importa – é quanto tempo resta. Se o UPS estima que só restam 10 minutos (ou o que configurarem) e ainda têm 50% de bateria, algo está errado. Alta carga, bateria degradada, ou estimativa do UPS maluca. O Eneru desliga antes que seja tarde. - Depletion Rate (O Trigger Mais Inteligente)
Este é particularmente genial. O Eneru mantém um histórico das leituras de bateria (janela configurável, default 5 minutos) e calcula a taxa real de descarga. Se a bateria está a descer mais de 15% por minuto (configurável), algo está muito errado e é melhor desligar.Exemplo real:
Tempo 0: Bateria a 80%
Tempo 5m: Bateria a 50%
Taxa: 30% em 5 min = 6%/min (OK)
vs.
Tempo 0: Bateria a 80%
Tempo 2m: Bateria a 50%
Taxa: 30% em 2 min = 15%/min (PERIGO!)
Isto apanha baterias velhas que de repente colapsam, picos de carga inesperados, ou UPS com problemas. Salvou-me pelo menos duas vezes desde que implementei.
- Extended Time on Battery (O Safety Net)
Mesmo que tudo pareça bem, se estiverem mais de 15 minutos (configurável) a correr em bateria, o Eneru pode desligar na mesma. Porquê? Porque baterias velhas podem parecer estáveis durante 20 minutos e depois falhar de repente. É o último safety net. - Cada trigger serve um propósito específico e compensa as falhas dos outros. É redundância de triggers, não redundância de hardware.
A arquitectura não-bloqueante: Porque notificações não podem atrasar shutdowns
Uma coisa que vi em muitas implementações caseiras (incluindo a minha primeira tentativa, confesso) é que as notificações bloqueiam o processo de shutdown. O código fica tipo:
send_discord_notification("UPS on battery!")
# espera resposta do Discord
# se a rede estiver em baixo, fica aqui pendurado
# enquanto a bateria continua a descer...
shutdown_vms() # só executa depois de enviar notificação
O Eneru faz isto de forma inteligente: fire-and-forget com worker thread. As notificações são postas numa queue e enviadas num thread separado. Se a rede estiver em baixo durante um corte de energia (spoiler: muitas vezes está, porque o router também está no UPS e pode estar a morrer), o shutdown continua na mesma sem atrasos.
Timeline típico (rede em baixo):
────────────────────────────────────────
0s │ Shutdown triggered
0.1s │ Notificação na queue (instant)
0.1s │ VMs a parar (não espera notificação)
15s │ VMs paradas
15s │ Containers a parar
30s │ Filesystems sync
35s │ Unmount com timeout
40s │ Remote servers shutdown
45s │ Grace period de 5s (tentativa de envio)
50s │ shutdown -h now
────────────────────────────────────────
Total: 50 segundos
Atraso por falha de rede: 0 segundos
Isto é crucial. Durante um corte de energia, cada segundo conta. Não podem permitir que uma falha de rede ou um timeout de Discord atrase o shutdown crítico.
A Orquestração Completa: Do Caos à Ordem
Vamos falar do que realmente acontece quando o Eneru deteta uma condição de shutdown:
Fase 1: Máquinas Virtuais (libvirt/KVM)
1. Lista todas as VMs em execução
2. Envia ACPI shutdown signal para cada uma
3. Espera até X segundos (configurável, default 30s)
4. Se alguma VM não parou, força destroy
5. Verifica que todas pararam antes de continuar
Isto é importante porque VMs não podem simplesmente ser “puxadas da ficha”. Bases de dados, filesystems, aplicações – tudo precisa de parar graciosamente.
Fase 2: Containers (Docker/Podman)
1. Deteta automaticamente o runtime disponível
2. Lista todos os containers em execução
3. Envia SIGTERM para parar graciosamente
4. Espera até X segundos (configurável, default 60s)
5. Se algum container não parou, força kill
O Eneru suporta Docker e Podman, e até consegue parar containers rootless do Podman se configurarem (útil em ambientes multi-user).
Fase 3: Filesystem Operations
1. sync (flush de todos os buffers para disco)
2. Para cada mountpoint configurado:
- Tenta unmount
- Se demorar mais que o timeout, força unmount (-l)
- Continua para o próximo mesmo que falhe
Isto evita hung mounts de NFS que podem travar todo o shutdown. Cada unmount tem o seu timeout individual.
Fase 4: Remote Servers
Para cada servidor remoto configurado:
1. Conecta via SSH (com timeout)
2. Executa comando de shutdown configurado
3. Não espera pela conclusão (non-blocking)
4. Continua para o próximo
Isto é perfeito para coordenar shutdown de NAS (Synology, QNAP, TrueNAS, Linux), servidores secundários, ou qualquer sistema ligado ao mesmo UPS.
Exemplo real do meu setup:
remote_servers:
- name: "NAS"
enabled: true
host: "192.168.1.100"
user: "admin"
shutdown_command: "sudo -i synoshutdown -s"
- name: "Backup Server"
enabled: true
host: "192.168.1.101"
user: "root"
shutdown_command: "sudo shutdown -h now" Fase 5: Local Shutdown
Finalmente, depois de tudo parado graciosamente, o próprio host desliga-se.
Setup Prático: Como Implementei no Meu Homelab
Vou partilhar o meu setup real, porque teoria é giro mas exemplos práticos valem mais. Nota que são dois grupos de computação e ambos são replicas uns dos outro.
Hardware
- Servidor: AMD EPYC com 256GB RAM
- UPS: Merlin/Gerin Smart-UPS 3500VA ligado via USB
- NAS Linux ligado ao mesmo UPS
- Router e switch também no UPS
Instalação
O Eneru tem packages nativos para Debian/Ubuntu e RHEL/Fedora. Uso Rocky Linux, então:
# Adicionar repositório EPEL (necessário para apprise)
sudo dnf install -y epel-release
# Adicionar repo do Eneru
sudo curl -o /etc/yum.repos.d/eneru.repo \
https://m4r1k.github.io/Eneru/rpm/eneru.repo
# Instalar
sudo dnf install eneru
O package instala mas não activa o serviço automaticamente (sensato – tem de se configurar primeiro).
Configuração
Editei /etc/ups-monitor/config.yaml com o meu setup:
# Configuração do UPS
ups:
name: "UPS@localhost" # NUT a correr localmente
check_interval: 1
max_stale_data_tolerance: 3
# Triggers de shutdown
triggers:
low_battery_threshold: 25 # mais conservador que o default
critical_runtime_threshold: 600
depletion:
window: 300
critical_rate: 15.0
grace_period: 90
extended_time:
enabled: true
threshold: 900 # 15 minutos
# Comportamento
behavior:
dry_run: false # depois de testar
# Logs
logging:
file: "/var/log/ups-monitor.log"
state_file: "/var/run/ups-monitor.state"
battery_history_file: "/var/run/ups-battery-history"
# Notificações (Discord webhook)
notifications:
title: "⚡ Homelab UPS"
avatar_url: "https://raw.githubusercontent.com/m4r1k/Eneru/main/docs/images/eneru-avatar.png"
timeout: 10
urls:
- "discord://webhook_id/webhook_token"
# VMs (tenho várias)
virtual_machines:
enabled: true
max_wait: 45 # dou mais tempo que o default
# Containers (muitos)
containers:
enabled: true
runtime: "auto" # deteta Docker automaticamente
stop_timeout: 60
# Filesystems
filesystems:
sync_enabled: true
unmount:
enabled: true
timeout: 20 # NFS pode ser lento
mounts:
- path: "/mnt/nas"
options: "-l" # force lazy unmount se necessário
- "/mnt/backup"
# Servidores remotos
remote_servers:
- name: "NAS"
enabled: true
host: "192.168.1.100"
user: "admin"
connect_timeout: 10
command_timeout: 30
shutdown_command: "sudo -i synoshutdown -s"
ssh_options:
- "-o StrictHostKeyChecking=no"
- "-o UserKnownHostsFile=/dev/null"
# Shutdown local
local_shutdown:
enabled: true
command: "shutdown -h now"
message: "UPS battery critical - emergency shutdown"
SSH Setup para Remote Servers
Para o shutdown remoto funcionar sem passwords:
# Gerar chave SSH (como root)
sudo su
ssh-keygen -t ed25519 -f ~/.ssh/id_ups_shutdown
# Copiar para o NAS
ssh-copy-id -i ~/.ssh/id_ups_shutdown.pub [email protected]
# No NAS, configurar sudo sem password
# /etc/sudoers.d/ups_shutdown
echo "admin ALL=(ALL) NOPASSWD: /usr/syno/sbin/synoshutdown -s" | \
sudo tee /etc/sudoers.d/ups_shutdown
sudo chmod 0440 /etc/sudoers.d/ups_shutdown
# Testar
sudo ssh [email protected] "sudo -i synoshutdown -s"
Validação e Testes
CRÍTICO: sempre testar em dry-run primeiro!
# Validar configuração
sudo python3 /opt/ups-monitor/ups_monitor.py --validate-config
# Testar notificações
sudo python3 /opt/ups-monitor/ups_monitor.py --test-notifications
# Dry-run (simula tudo sem executar)
sudo python3 /opt/ups-monitor/ups_monitor.py --dry-run
Então desconectei o UPS da corrente e observei os logs:
[INFO] Power lost - UPS on battery (OB)
[INFO] Battery: 100%, Runtime: 3600s, Load: 35%
[INFO] Monitoring battery depletion rate...
[DRY-RUN] Would stop 17 virtual machines
[DRY-RUN] Would stop 23 Docker containers
[DRY-RUN] Would sync filesystems
[DRY-RUN] Would unmount /mnt/nas [DRY-RUN] Would unmount /mnt/backup
[DRY-RUN] Would shutdown remote server: Synology NAS
[DRY-RUN] Would execute: shutdown -h now
Perfeito. Tudo funciona. Desativei o dry-run e ativei o serviço:
sudo systemctl enable eneru.service
sudo systemctl start eneru.service
sudo systemctl status eneru.service
Cenários Reais que o Eneru Já Me Salvou
Desde que implementei o Eneru (depois do apagão ibérico), já houve três situações onde provei o seu valor:
Cenário 1: Corte de Energia Planeado (Que Não Me Avisaram)
A EDP fez manutenção na rede. Durou 25 minutos. O Eneru:
- Detetou power loss
- Monitorizou durante 15 minutos
- Extended time trigger activou-se
- Shutdown ordenado de tudo
- Zero perda de dados
- Quando a energia voltou, tudo arrancou normalmente
Cenário 2: Bateria do UPS a Morrer
A bateria já tinha 4 anos. Durante um corte breve de energia, começou a descarregar muito mais rápido que o esperado. O depletion rate trigger apanhou isto:
Battery: 65%
Runtime estimate: 20 minutes (mentira)
Depletion rate: 18%/min (PERIGO!)
Eneru triggered shutdown
Fez shutdown quando ainda havia 50% de bateria. Boa coisa, porque a bateria colapsou completamente 2 minutos depois. Se tivesse esperado pelos 20% de threshold, teria tido um estatelanço épico.
Cenário 3: Problema de Rede Durante Corte
Corte de energia. Um dos switches, embora no UPS, ficou instável. Rede local intermitente, pois o bonding começou a fazer flapping.
O Eneru:
- Notificações falharam (rede em baixo)
- Não esperou pelas notificações
- Continuou com o shutdown normalmente
- Zero atraso por problemas de rede
Métricas e Monitorização
O Eneru expõe métricas em /var/run/ups-monitor.state:
{
"timestamp": "2025-12-29T15:30:45",
"ups_status": "OL",
"battery_charge": 100,
"battery_runtime": 3600,
"battery_voltage": 13.5,
"input_voltage": 230,
"load_percent": 35,
"time_on_battery": 0,
"depletion_rate": 0.0
}
Integrei isto no meu Grafana para monitorização contínua. Assim vejo:
- Histórico de bateria
- Eventos de power loss
- Tendências de depletion
- Health da bateria ao longo do tempo
Custos Evitados vs Investimento
Vamos falar de números, porque malta de IT gosta de ROI:
Investimento:
- Tempo de setup: 2 horas (incluindo testes)
- Custo de software: 0€ (é open source, MIT license)
- Manutenção: praticamente zero (depois de configurado, esquece)
Custos evitados (baseado na minha experiência sem orquestração):
- Tempo de recovery manual: 8 horas @ 50€/hora = 400€
- Dados perdidos/corruptos: incalculável
- Downtime de serviços: 2 dias
- Stress e noites perdidas: priceless
ROI: ridiculamente positivo.
Alternativas e Porque Escolhi o Eneru
Antes do Eneru, avaliei várias opções:
Scripts Bash Caseiros
Pros: Total controlo, zero dependências Cons: Difícil manter, sem triggers inteligentes, bloqueante, sem notificações robustas
NUT’s upsmon + upssched
Pros: Vem com o NUT, bem testado Cons: Configuração complexa, menos flexível, sem orquestração de VMs/containers out-of-the-box
Solutions Comerciais
Pros: Suporte, GUI bonitas Cons: Caras, vendor lock-in, overkill para homelabs
PowerPanel (APC)
Pros: Oficial da APC Cons: Apenas Windows/GUI, não serve para ambientes Linux headless
O Eneru ganhou porque:
- Open source (posso ver e modificar o código)
- Python moderno e bem estruturado
- Triggers inteligentes prontos a usar
- Orquestração completa de VMs/containers/remote servers
- Notificações via Apprise (100+ serviços suportados)
- Non-blocking architecture
- Instalação simples via packages
- Configuração clara em YAML
- Comunidade activa (GitHub)
Recomendações Finais
Se têm um homelab com:
- Múltiplas VMs ou containers
- Dados importantes
- Serviços críticos (mesmo que só para vocês)
- Um UPS (e se não têm, comprem um!)
Precisam de orquestração de shutdown automática. Não é opcional. É questão de tempo até terem um corte de energia no momento errado.
O Eneru resolve isto de forma elegante, testada, e open source. A instalação demora 30 minutos. A configuração demora 1 hora. O dry-run testing demora 30 minutos. Total: 2 horas para proteger anos de trabalho no vosso homelab.
Para quem vai implementar (e deviam), aqui está a checklist de implementação que usei:
Fase 1: Preparação
- [ ] UPS ligado e a funcionar com NUT
- [ ] Testar
upsc UPS@hostfunciona - [ ] Backups recentes (sempre!)
- [ ] Janela de manutenção disponível
Fase 2: Instalação
- [ ] Package instalado
- [ ] Dependências verificadas
- [ ] Serviço desabilitado (configurar primeiro)
Fase 3: Configuração
- [ ] config.yaml editado
- [ ] Triggers ajustados ao vosso UPS
- [ ] Remote servers configurados (se aplicável)
- [ ] SSH keys configuradas
- [ ] Notificações configuradas
- [ ]
--validate-configpassa
Fase 4: Testes
- [ ]
--test-notificationsfunciona - [ ]
--dry-runcom UPS desligado da corrente - [ ] Observar logs durante simulação
- [ ] Verificar que todas as fases executam
- [ ] Confirmar notificações chegam
Fase 5: Produção
- [ ] Desativar dry-run na config
- [ ] Enable e start do serviço
- [ ] Monitorizar logs nas primeiras 24h
- [ ] Documentar o setup (para quando precisarem daqui a 1 ano)
Casos Edge e Gotchas
Algumas notas que apanhei no processo de montar a solução:
Gotcha 1: NFS Hung Mounts
Se têm NFS mounts e o servidor que está a servir esse NFS não é dos grupos do NAS(es) que são desligados no fim, desliga antes do cliente, podem ficar com hung mounts que bloqueiam o shutdown. Solução:
filesystems:
unmount:
mounts:
- path: "/mnt/nas"
options: "-l" # lazy unmount
Gotcha 2: VMs com PCI Passthrough
VMs com dispositivos PCI em passthrough podem precisar de mais tempo para parar. Aumentem o max_wait:
virtual_machines:
max_wait: 60 # mais tempo para VMs complexas
Gotcha 3: Containers com Volumes
Containers com volumes grandes podem demorar a fazer flush de dados. Aumentem o stop_timeout:
containers:
stop_timeout: 120
Gotcha 4: Bateria Envelhecida
Se a bateria do UPS já tem mais de 3-4 anos, sejam mais conservadores nos triggers:
triggers:
low_battery_threshold: 30 # mais alto
critical_runtime_threshold: 900 # 15 min em vez de 10
extended_time:
threshold: 600 # 10 min em vez de 15
Gotcha 5: Multiple UPS
Se têm múltiplos UPS, cada sistema deve ter a sua instância do Eneru a monitorizar o UPS local. Não tentem centralizar – se o servidor central morrer, os outros ficam sem protecção.
Estatísticas do Meu Setup
Desde que implementei o Eneru (4 meses):
Eventos de Power Loss: 7
- 5 cortes breves (<5 min) – nenhum shutdown necessário
- 2 cortes longos (>15 min) – shutdowns automáticos bem sucedidos
Shutdowns Executados: 2
- Tempo médio de shutdown completo: 52 segundos
- VMs paradas: 17 (em cada shutdown)
- Containers parados: ~20-25 (varia)
- Servidores remotos coordenados: 2 (NAS)
- Dados perdidos: 0 bytes
- Filesystem corruption: 0 casos
- Noites de sono perdidas: 0 (em comparação com as 3 do evento original) :]
Falsos Positivos: 0
- Os triggers múltiplos são suficientemente robustos
- Nunca tive shutdown desnecessário
Futuro e Melhorias
O que gostaria de ver no futuro (e posso até contribuir, já que é open source):
- Integração com Home Assistant – para quem tem automação doméstica
- Métricas Prometheus – exportador nativo seria fantástico
- Web Dashboard – GUI simples para monitorizar status em tempo real. Estou a escrever alguma coisa para o efeito com a ajuda do QwenCoder/Codestral.
- Hooks Customizados – executar scripts custom em cada fase
- Machine Learning – previsão de falha de bateria baseada em histórico
Mas honestamente, mesmo sem isto, o Eneru já faz o trabalho perfeitamente.
A Lição Final
Quando comecei o meu homelab há anos, pensava que um UPS era suficiente. “Tenho UPS, estou protegido”, pensava eu. Mal sabia. Ignorância é uma benção quando dormimos tranquilos.
Um UPS sem orquestração de shutdown é como ter um salva-vidas mas não saber nadar – ajuda, mas não é suficiente. Especialmente em ambientes modernos com VMs, containers, e sistemas distribuídos ou com múltiplos grupos de UPS e hosts envolvidos.
O Eneru resolve isto. É a diferença entre:
- “Oh não, houve um corte de energia, vou passar o fim de semana a recuperar sistemas”
- “Houve um corte de energia? Nem reparei, o Eneru tratou de tudo”
E essa paz de espírito, para quem gere um homelab onde correm serviços importantes (mesmo que só para vocês), não tem preço.
Recursos e Links
- GitHub: https://github.com/m4r1k/Eneru
- Documentação Completa: README.md no repositório
- NUT (Network UPS Tools): https://networkupstools.org/
- Apprise (Notificações): https://github.com/caronc/apprise
TL;DR para Quem Saltou Para o Fim
- Homelabs precisam de orquestração de shutdown automática quando falta energia
- O Eneru é um daemon Python que monitoriza UPS via NUT
- Usa múltiplos triggers inteligentes (não só bateria baixa)
- Orquestra shutdown de VMs, containers, filesystems, e servidores remotos
- Notificações não bloqueantes via 100+ serviços
- Open source, fácil de instalar, configurar, e testar
- Instalem antes que aprendam à maneira difícil como eu
- Levem 2 horas agora ou percam 2 dias depois – a escolha é vossa
Até ao próximo post, e lembrem-se: em IT, não é questão de se vão ter um corte de energia no momento errado, é questão de quando. Estejam preparados.
Abraço,
Nuno
P.S.: Se implementarem o Eneru e salvarem o vosso homelab de um desastre, partilhem a história nos comentários. Adoro histórias de “isto salvou-me a vida”.
P.P.S: Sim, o nome Eneru vem do personagem de One Piece que controla electricidade. O autor tem bom gosto em anime e em naming de software. Respeito.
P.P.P.S: A bateria do meu UPS todos os dias morre mais um pouco O Eneru vai-me proteger até lá. Vocês já têm o vosso sistema de orquestração?