ElasticSearch – Lab Edition – Versão 7.2
Olá a todos,
No seguimento do meu post anterior sobre uma stack ELK que pode ser consultado aqui, venho agora atualizar o mesmo para a ultima versão disponível do Elasticsearch – 7.2
Tudo isto começou inicialmente, quando me foi pedido para fazer um post sobre elastic search, e como colocar o ambiente a funcionar num ambiente finito, contido e sobretudo portátil, que possa ser utilizado como lab da solução, para testar configurações e alterações em ambientes produtivos maiores ou até para apresentações e POC’s.
Como certamente sabem, o elastic search está a se afirmar como “o” search engine de dados e bigdata.
Elasticsearch is an open-source, broadly distributable, scalable, enterprise-grade search engine. Accessible through an extensive and elaborate API, elastic search can power extremely fast searches that support your data discovery applications.
Para conhecerem melhor tudo o que engloba, recomento que leiam este artigo que aborda muito bem os pontos fortes do produto, do ponto de vista do power user.

No caso em mãos e que que irá ser apresentado neste post, irei configurar uma instância para receber dados de syslog dos meus servidores de homelab.
A arquitetura pretendida é algo como: Servidor gera logs, o beats obtém logs e metricas, envia para o logstash que os classifica, processa e arruma em índices dentro do ElasticSearch, que em seguida podem ser consultados e trabalhados via a componente do Kibana.
O esquema em si é relativamente simples, tendo em conta que iremos para o nosso lab, utilizar apelas os :
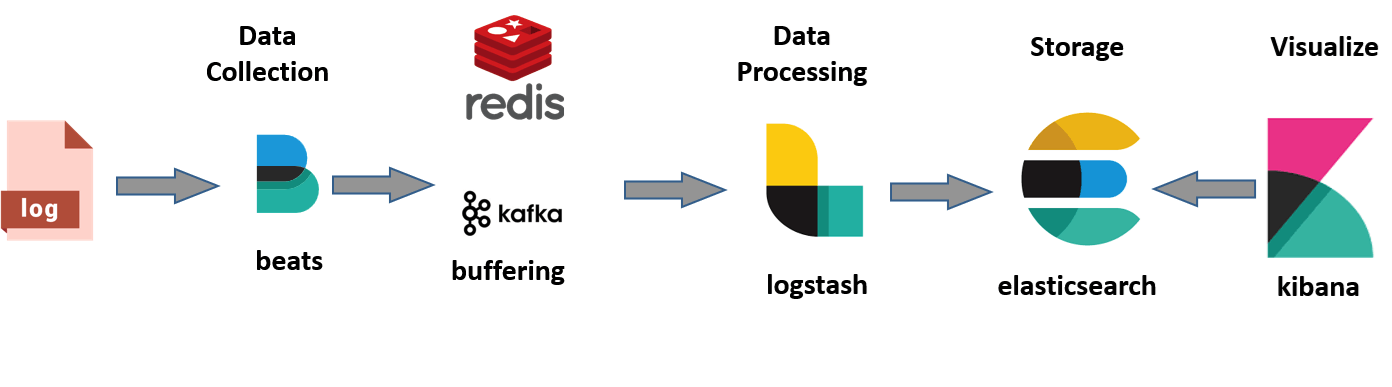
Em primeiro lugar, será necessário configurar um container em Centos (7.5 – 4GB RAM/4vCPUs/100GB disco), tendo cuidado para passar ao host o seguinte parâmetro de kernel via sysctl:
vm.max_map_count=262144
Em seguida, e já dentro do container iremos descarregar do site da Oracle, o java JDK 1.8.X que instalaremos.
Nota: poderá haver a necessidade de exportar a flag JAVACMD desde o profile:
# cat /etc/profile | grep JAVACMD export JAVACMD=`which java`
É agora altura de proceder a instalação do produto. Para tal efectuar:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Criar os repos do produto com o seguinte conteúdo:
[elasticsearch-7.x] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
Após é instalar o produto:
# yum install elasticsearch # yum install kibana # yum install logstash
Finalmente a secção da configuração que é relativamente simples, embora existam diferenças entre as versões anteriores e as correntes.
É igualmente importante referir que o FQDN do servidor estar configurado corretamente ao nível do DNS para evitar falhas.
O ficheiro de configuração para o engine do elasticsearch é:
# cat /etc/elasticsearch/elasticsearch.yml
cluster.name: "elasticSearch" node.name: "elastic.net.xpto" network.host: localhost path.data: /mnt/elasticsearch/data path.logs: /var/log/elasticsearch/logs discovery.zen.minimum_master_nodes: 1 action.auto_create_index: true
Nota: as diretorias de path.data e path.logs devem ser criadas manualmente, com as permissões apropriadas: elasticsearch.elasticsearch.
O ficheiro de configuração para o logstash é:
# cat /etc/logstash/logstash.yml # Node identity node.name: "elastic.net.xpto" #Data and Log paths path.data: /var/lib/logstash path.logs: /var/log/logstash # Pipeline Settings pipeline.batch.size: 125 pipeline.batch.delay: 5 pipeline.workers: 2 pipeline.output.workers: 1 pipeline.batch.size: 100 pipeline.batch.delay: 3 ## Pipeline Configuration Settings path.config: /etc/logstash/conf.d config.reload.automatic: true #How often to check if the pipeline configuration has changed (in seconds) config.reload.interval: 3 # Debugging Settings log.level: debug
Como é no logstash que iremos definir o índice para onde enviamos os nossos lota, no diretório /etc/logstash/conf.d, colocaremos o nosso harvester de syslog:
# cat /etc/logstash/conf.d/log.conf
input {
tcp {
port => 15514
type => syslog
}
udp {
port => 15514
type => syslog
} }
output {
elasticsearch {
hosts => ["http://elastic.net.xpto:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}
}
Nota: É definido o tipo (type – pode ter o nome que se deseje desde que seja reflectido no kibana), o destino (host) para onde o logstash irá enviar em bulk os dados e o índice (index) onde os dados vão ser carregados.
Esta configuração irá abrir no servidor, os portos TCP e UDP 15514, para onde deverão apontar os vossos syslogs.
Para finalizar a configuração, será altura de configurar o Kibana:
# cat /etc/kibana/kibana.yml server.port: 5601 server.name: "elastic.net.xpto" server.host: "172.16.4.154" ### NOTA IP DE BIND WEBGUI elasticsearch.url: "http://elastic.net.xpto:9200" logging.dest: /var/opt/elastic/kibana/logs/kibana.log
Em seguida garantir o arranque dos vossos componentes:
systemctl enable elasticsearch systemctl enable logstash systemctl enable kibana systemctl start elasticsearch systemctl start logstash systemctl start kibana
Finalmente, configurem os vossos syslogs (no meu caso rsyslog) para enviar para o servidor de elastic, no porto definido anteriormente no logstash:
cat /etc/rsyslog.conf | grep -i @ *.* @@elastic.net.xpto:5514
Assim que o logstash receba dados nessa porta e o envie para o índice correto, o Kibana irá o mostrar como é visível no printscreen abaixo.
Caso o kibana não esteja a receber logs, não irá criar automaticamente o índice definido no logstash.
Se tiverem feito tudo corretamente, o vosso acesso ao WebUI do Kibana estará a um URL de distancia – http://IP:5601 – no meu caso http://elastic.net.xpto:5601
Nota: Se por acaso algum dos componentes não arrancar corretamente, validem se as diretorias que definiram nos ficheiros de configuração existem.
Os logs do produto são extremamente completos e descritivos das dores aplicacionais.
Se necessitarem de enviar dados ou outputs que não suportem serem enviados via syslog, recomendo que vejam o filebeats (da elastic) que está disponível para download via repositório yum ou manualmente.
Para logs windows, também existem agentes, ou caso prefiram o winlogd.
Chegamos agora a parte de controlar a copiosa utilização de memoria pela stack ELK: Se usam o elastic no vosso dia a dia devem ter notado no consumo de memória, que torna a sua presença num homelab algo impraticável para configurações mais modestas, ou para homelabs mobile.
Existem algumas sugestões dadas pela Elastic e pela comunidade para o tema. Desde configuração de parâmetros JAVA, a alteração de memory locking and shards.
No meu caso, decidi reduzir os limites da JVM, sabendo que isso me coloca mais perto de erros de OOM.
Para tal nada mais simples:
Alterei no ficheiro /etc/security/limits.conf o seguinte valor:
elasticsearch hard memlock 100000
E no ficheiro /etc/default/elasticsearch os valores:
ES_HEAP_SIZE=128m MAX_LOCKED_MEMORY=100000 ES_JAVA_OPTS=-server
Com isto, fui de um consumo de 4GB de memória efetiva, para 1GB. A diferença é para mim apreciável.
Como conclusão deste post, temos aqui uma demonstração muito simples de como criar um ambiente de harvesting & processamento de logs apenas em uma máquina.
Tipicamente a elastic suporta apenas ambientes em multi tier, pelo que planeamento avançado é recomendado caso seja necessário suporte ou tenha dados críticos de negócio.
Experimentem, usem e divirtam-se. Conto assim que me for humanamente possível colocar metodologia de dashboards e alarmistica (por exemplo para ataque a instâncias de apache).
Caso necessitem de ajuda terei o maior gosto em vos auxiliar no que puder. Já sabem onde me encontrar.
Até ao próximo post!
Nuno